


RainFly
明确一个目标,这很重要!


- 最新文章
-
 Ubuntu安装远程桌面并启用浏览器自动化 Ubuntu 远程桌面 + Playwright 自动化完整指南 适用系统:Ubuntu 22.04 LTS 场景:通过 Windows 远程桌面连接 Ubuntu,运行 Playwright 自动化脚本长期挂机 目录 安装远程桌面(xrdp + xfce4) Windows 连接远程桌面 安装 Google Chrome 克隆项目 & 配置 Python 环境 运行自动化脚本 用 screen 长期挂机 常见问题排查 一、安装远程桌面 1.1 安装 xrdp + xfce4 # 安装 xfce4 桌面环境(轻量、兼容性好) apt install xrdp xfce4 xfce4-goodies -y # 设置 root 使用 xfce4 echo "xfce4-session" > /root/.xsession chmod +x /root/.xsession # 启动并设置开机自启 systemctl enable xrdp systemctl start xrdp # 开放 3389 端口 ufw allow 3389/tcp ufw reload 1.2 验证服务状态 systemctl status xrdp ss -tlnp | grep 3389 看到 active (running) 和 0.0.0.0:3389 即为成功。 1.3 查看服务器 IP hostname -I # 或 ip addr show 二、Windows 连接远程桌面 2.1 打开远程桌面 Win + R → 输入 mstsc → 回车 2.2 填写连接信息 计算机(C):192.168.1.x:3389 ← 填你的服务器 IP 点击"连接"。 2.3 登录界面填写 Session: Xorg ← 必须选这个 username: root password: 你的root密码 黑屏解决方法: echo "xfce4-session" > /root/.xsession systemctl restart xrdp 断开后重新连接即可。 三、安装 Google Chrome # 下载 wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb # 安装 apt install ./google-chrome-stable_current_amd64.deb -y # 验证 google-chrome --version 四、克隆项目 & 配置 Python 环境 4.1 配置 GitHub SSH(推荐,一劳永逸) # 生成 SSH 密钥 ssh-keygen -t ed25519 -C "你的邮箱" # 一路回车 # 查看公钥 cat ~/.ssh/id_ed25519.pub 将公钥添加到 GitHub:https://github.com/settings/ssh/new # 测试连接 ssh -T git@github.com # 克隆项目(SSH 方式) git clone git@github.com:用户名/仓库名.git 4.2 使用 Token 方式(备选) git clone https://你的token@github.com/用户名/仓库名.git Token 生成地址:https://github.com/settings/tokens(勾选 repo 权限) 4.3 创建 Python 虚拟环境 # 进入项目目录 cd /home/linux_do_welfare # 安装 venv(如未安装) apt install python3-venv -y # 创建虚拟环境 python3 -m venv venv # 激活虚拟环境 source venv/bin/activate # 成功后命令行前会显示 (venv) 4.4 安装依赖 # 升级 pip pip install --upgrade pip # 安装项目依赖 pip install -r requirements.txt # 安装 Playwright 浏览器 playwright install chromium # 安装系统依赖 playwright install-deps 五、运行自动化脚本 ⚠️ 以下操作必须在远程桌面(xrdp 图形界面)的终端中执行,不能在 SSH 黑窗口中执行。 5.1 打开远程桌面终端 在 Xfce4 桌面右键 → 打开终端 5.2 终端 1:启动 Chrome(带调试端口) google-chrome --remote-debugging-port=9222 --no-sandbox --disable-dev-shm-usage Chrome 窗口打开后,手动登录 linux.do 账号 Cookie 会自动保存,下次无需再次登录 5.3 终端 2:运行脚本 再开一个终端(右键桌面 → 打开终端): cd /home/linux_do_welfare source venv/bin/activate python 自动监听福利羊毛.py 看到以下输出说明运行成功: AI分类客户端初始化成功 Linux.do 福利羊毛监听任务开始 目标: 每隔 30 秒检查一次福利羊毛板块最新帖子 连接已打开的 Chrome: 127.0.0.1:9222 六、用 screen 长期挂机 关掉远程桌面窗口后脚本会停止,用 screen 可以让脚本持续在后台运行。 6.1 安装 screen apt install screen -y 6.2 启动流程 # 新建 screen 会话 screen -S welfare # 在 screen 里启动 Chrome(后台) google-chrome --remote-debugging-port=9222 --no-sandbox --disable-dev-shm-usage & # 等待 Chrome 启动 sleep 3 # 运行脚本 cd /home/linux_do_welfare source venv/bin/activate python 自动监听福利羊毛.py 6.3 断开 screen(脚本继续运行) 按 Ctrl+A,再按 D 此时可以安全关闭远程桌面,脚本在后台继续运行。 6.4 重新连接查看 # 查看所有 screen 会话 screen -ls # 重新进入 screen -r welfare 6.5 停止脚本 # 进入 screen 后 Ctrl+C # 停止脚本 # 退出并销毁 screen exit 七、常见问题排查 远程桌面连接后黑屏 echo "xfce4-session" > /root/.xsession systemctl restart xrdp 断开重连即可。 Chrome 报错:Missing X server or $DISPLAY 原因:在 SSH 窗口里运行了需要图形界面的命令。 解决:必须在远程桌面的终端里运行 Chrome,不要在 SSH 里运行。 脚本报错:无法找到浏览器可执行文件 # 确认 Chrome 路径 which google-chrome # 查看脚本配置,确认路径正确 grep -n "chrome" 自动监听福利羊毛.py | head -20 pip install 报错 # 使用国内镜像加速 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple GitHub 克隆鉴权失败 不要用密码,改用 SSH 或 Token 方式,参考第四章。 快速参考 操作 命令 激活虚拟环境 source venv/bin/activate 退出虚拟环境 deactivate 启动 Chrome google-chrome --remote-debugging-port=9222 --no-sandbox 运行脚本 python 自动监听福利羊毛.py 新建 screen screen -S welfare 断开 screen Ctrl+A 然后 D 恢复 screen screen -r welfare 重启 xrdp systemctl restart xrdp 查看服务器 IP hostname -I 生成时间:2026-05-22
Ubuntu安装远程桌面并启用浏览器自动化 Ubuntu 远程桌面 + Playwright 自动化完整指南 适用系统:Ubuntu 22.04 LTS 场景:通过 Windows 远程桌面连接 Ubuntu,运行 Playwright 自动化脚本长期挂机 目录 安装远程桌面(xrdp + xfce4) Windows 连接远程桌面 安装 Google Chrome 克隆项目 & 配置 Python 环境 运行自动化脚本 用 screen 长期挂机 常见问题排查 一、安装远程桌面 1.1 安装 xrdp + xfce4 # 安装 xfce4 桌面环境(轻量、兼容性好) apt install xrdp xfce4 xfce4-goodies -y # 设置 root 使用 xfce4 echo "xfce4-session" > /root/.xsession chmod +x /root/.xsession # 启动并设置开机自启 systemctl enable xrdp systemctl start xrdp # 开放 3389 端口 ufw allow 3389/tcp ufw reload 1.2 验证服务状态 systemctl status xrdp ss -tlnp | grep 3389 看到 active (running) 和 0.0.0.0:3389 即为成功。 1.3 查看服务器 IP hostname -I # 或 ip addr show 二、Windows 连接远程桌面 2.1 打开远程桌面 Win + R → 输入 mstsc → 回车 2.2 填写连接信息 计算机(C):192.168.1.x:3389 ← 填你的服务器 IP 点击"连接"。 2.3 登录界面填写 Session: Xorg ← 必须选这个 username: root password: 你的root密码 黑屏解决方法: echo "xfce4-session" > /root/.xsession systemctl restart xrdp 断开后重新连接即可。 三、安装 Google Chrome # 下载 wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb # 安装 apt install ./google-chrome-stable_current_amd64.deb -y # 验证 google-chrome --version 四、克隆项目 & 配置 Python 环境 4.1 配置 GitHub SSH(推荐,一劳永逸) # 生成 SSH 密钥 ssh-keygen -t ed25519 -C "你的邮箱" # 一路回车 # 查看公钥 cat ~/.ssh/id_ed25519.pub 将公钥添加到 GitHub:https://github.com/settings/ssh/new # 测试连接 ssh -T git@github.com # 克隆项目(SSH 方式) git clone git@github.com:用户名/仓库名.git 4.2 使用 Token 方式(备选) git clone https://你的token@github.com/用户名/仓库名.git Token 生成地址:https://github.com/settings/tokens(勾选 repo 权限) 4.3 创建 Python 虚拟环境 # 进入项目目录 cd /home/linux_do_welfare # 安装 venv(如未安装) apt install python3-venv -y # 创建虚拟环境 python3 -m venv venv # 激活虚拟环境 source venv/bin/activate # 成功后命令行前会显示 (venv) 4.4 安装依赖 # 升级 pip pip install --upgrade pip # 安装项目依赖 pip install -r requirements.txt # 安装 Playwright 浏览器 playwright install chromium # 安装系统依赖 playwright install-deps 五、运行自动化脚本 ⚠️ 以下操作必须在远程桌面(xrdp 图形界面)的终端中执行,不能在 SSH 黑窗口中执行。 5.1 打开远程桌面终端 在 Xfce4 桌面右键 → 打开终端 5.2 终端 1:启动 Chrome(带调试端口) google-chrome --remote-debugging-port=9222 --no-sandbox --disable-dev-shm-usage Chrome 窗口打开后,手动登录 linux.do 账号 Cookie 会自动保存,下次无需再次登录 5.3 终端 2:运行脚本 再开一个终端(右键桌面 → 打开终端): cd /home/linux_do_welfare source venv/bin/activate python 自动监听福利羊毛.py 看到以下输出说明运行成功: AI分类客户端初始化成功 Linux.do 福利羊毛监听任务开始 目标: 每隔 30 秒检查一次福利羊毛板块最新帖子 连接已打开的 Chrome: 127.0.0.1:9222 六、用 screen 长期挂机 关掉远程桌面窗口后脚本会停止,用 screen 可以让脚本持续在后台运行。 6.1 安装 screen apt install screen -y 6.2 启动流程 # 新建 screen 会话 screen -S welfare # 在 screen 里启动 Chrome(后台) google-chrome --remote-debugging-port=9222 --no-sandbox --disable-dev-shm-usage & # 等待 Chrome 启动 sleep 3 # 运行脚本 cd /home/linux_do_welfare source venv/bin/activate python 自动监听福利羊毛.py 6.3 断开 screen(脚本继续运行) 按 Ctrl+A,再按 D 此时可以安全关闭远程桌面,脚本在后台继续运行。 6.4 重新连接查看 # 查看所有 screen 会话 screen -ls # 重新进入 screen -r welfare 6.5 停止脚本 # 进入 screen 后 Ctrl+C # 停止脚本 # 退出并销毁 screen exit 七、常见问题排查 远程桌面连接后黑屏 echo "xfce4-session" > /root/.xsession systemctl restart xrdp 断开重连即可。 Chrome 报错:Missing X server or $DISPLAY 原因:在 SSH 窗口里运行了需要图形界面的命令。 解决:必须在远程桌面的终端里运行 Chrome,不要在 SSH 里运行。 脚本报错:无法找到浏览器可执行文件 # 确认 Chrome 路径 which google-chrome # 查看脚本配置,确认路径正确 grep -n "chrome" 自动监听福利羊毛.py | head -20 pip install 报错 # 使用国内镜像加速 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple GitHub 克隆鉴权失败 不要用密码,改用 SSH 或 Token 方式,参考第四章。 快速参考 操作 命令 激活虚拟环境 source venv/bin/activate 退出虚拟环境 deactivate 启动 Chrome google-chrome --remote-debugging-port=9222 --no-sandbox 运行脚本 python 自动监听福利羊毛.py 新建 screen screen -S welfare 断开 screen Ctrl+A 然后 D 恢复 screen screen -r welfare 重启 xrdp systemctl restart xrdp 查看服务器 IP hostname -I 生成时间:2026-05-22 -
 agent开发之一(skill,tool,mcp相互关联) 四者之间的关系可以这样理解: Agent 是最顶层的"大脑",负责规划目标、拆分任务、决定下一步做什么。它不亲自执行,而是调用下层能力。 Skill 是对"怎么做某件事"的高层封装。它通常包含提示模板、推理链、或一段固定的执行逻辑,让 Agent 复用经验而不必每次从头构建。Skill 本身可以在内部编排多个 Tool 的调用顺序。 Tool 是最基础的原子接口——一个可调用的函数,有明确的输入输出。Agent 可以直接调用 Tool,Skill 也可以在内部组合调用多个 Tool。 MCP(Model Context Protocol) 是连接 AI 层与外部世界的协议标准。它把外部能力规范地暴露为三类端点: Resources — 提供文件、数据库记录等上下文内容 Tools — 注册可被调用的函数(这是 MCP 的 Tool,与上面 Tool 层对应) Prompts — 管理可复用的提示模板 一句话总结关系链:Agent 通过 Skill(策略层)和 Tool(执行层)发出意图,Tool 通过 MCP 协议与外部 API、数据库、文件系统交互,完成真实世界的操作。 Skill 是对"如何完成某类任务"的高层封装——它不是一个函数,而是一段经验。 最直观的区分方式:Tool 回答"能做什么",Skill 回答"怎么做好"。 Tool 是什么?它如何与外部系统交互? Tool 的三个核心属性,缺一不可: name 是 Tool 的唯一标识,Agent 靠它选择工具,比如 search_web、read_file、send_email。 schema 定义了入参的结构和类型(通常是 JSON Schema),调用前会对参数做验证,防止无效请求打到外部系统。 handler 是实际执行体,里面写着如何发 HTTP 请求、如何查询数据库、如何读写文件。 这层对 Agent 完全透明——Agent 只看到 schema,不知道 handler 怎么实现的。 与外部系统的交互方式本质上没有限制,常见的有: REST/GraphQL API — 通过 HTTP 调用第三方服务 数据库 — 执行 SQL 或 NoSQL 查询 文件系统 — 读取、写入、列举本地或远程文件 subprocess / shell — 执行系统命令 其他 Tool / MCP 服务 — Tool 也可以嵌套调用 最关键的设计原则:Tool 是原子的、无状态的(理想情况下),每次调用都是独立的输入→执行→输出,这让 Agent 可以安全地组合、重试、并行调用多个 Tool,而不用担心副作用叠加。
agent开发之一(skill,tool,mcp相互关联) 四者之间的关系可以这样理解: Agent 是最顶层的"大脑",负责规划目标、拆分任务、决定下一步做什么。它不亲自执行,而是调用下层能力。 Skill 是对"怎么做某件事"的高层封装。它通常包含提示模板、推理链、或一段固定的执行逻辑,让 Agent 复用经验而不必每次从头构建。Skill 本身可以在内部编排多个 Tool 的调用顺序。 Tool 是最基础的原子接口——一个可调用的函数,有明确的输入输出。Agent 可以直接调用 Tool,Skill 也可以在内部组合调用多个 Tool。 MCP(Model Context Protocol) 是连接 AI 层与外部世界的协议标准。它把外部能力规范地暴露为三类端点: Resources — 提供文件、数据库记录等上下文内容 Tools — 注册可被调用的函数(这是 MCP 的 Tool,与上面 Tool 层对应) Prompts — 管理可复用的提示模板 一句话总结关系链:Agent 通过 Skill(策略层)和 Tool(执行层)发出意图,Tool 通过 MCP 协议与外部 API、数据库、文件系统交互,完成真实世界的操作。 Skill 是对"如何完成某类任务"的高层封装——它不是一个函数,而是一段经验。 最直观的区分方式:Tool 回答"能做什么",Skill 回答"怎么做好"。 Tool 是什么?它如何与外部系统交互? Tool 的三个核心属性,缺一不可: name 是 Tool 的唯一标识,Agent 靠它选择工具,比如 search_web、read_file、send_email。 schema 定义了入参的结构和类型(通常是 JSON Schema),调用前会对参数做验证,防止无效请求打到外部系统。 handler 是实际执行体,里面写着如何发 HTTP 请求、如何查询数据库、如何读写文件。 这层对 Agent 完全透明——Agent 只看到 schema,不知道 handler 怎么实现的。 与外部系统的交互方式本质上没有限制,常见的有: REST/GraphQL API — 通过 HTTP 调用第三方服务 数据库 — 执行 SQL 或 NoSQL 查询 文件系统 — 读取、写入、列举本地或远程文件 subprocess / shell — 执行系统命令 其他 Tool / MCP 服务 — Tool 也可以嵌套调用 最关键的设计原则:Tool 是原子的、无状态的(理想情况下),每次调用都是独立的输入→执行→输出,这让 Agent 可以安全地组合、重试、并行调用多个 Tool,而不用担心副作用叠加。 -
 OpenSpec 使用手册 OpenSpec 使用手册 基于项目的实践经验总结。 1. 简介 OpenSpec 是一个规范驱动开发(Spec-Driven Development, SDD)框架,专为 AI 编程助手设计。它通过在编写代码之前先定义规范,确保人与 AI 对需求达成一致。 1.1 什么是规范驱动开发? 传统开发流程通常是:需求 → 直接编码 → 测试 → 交付。 规范驱动开发的流程是:需求 → 编写规范 → 验证规范 → 编码实现。 这种方式的优势在于: 人与 AI 先就"做什么"达成一致,避免返工 规范文档作为契约,减少沟通成本 规范可以版本化管理,便于追溯 1.2 核心理念 理念 含义 流动而非僵化 文档可以随时更新,没有严格的阶段门槛 迭代而非瀑布 支持增量添加需求,逐步完善 简单而非复杂 只需要 Markdown 文件,无复杂工具链 兼顾存量与新建项目 既适用于已有代码库(Brownfield),也适用于全新项目(Greenfield) 术语解释: Brownfield(存量项目):指已经存在的、有历史代码的项目。OpenSpec 可以逐步引入,不必重构现有代码。 Greenfield(新建项目):指从零开始的新项目。OpenSpec 可以从一开始就建立规范体系。 1.3 核心价值 先达成一致再构建 在编写代码之前,人与 AI 先就规范达成共识 避免 AI 理解偏差导致的返工 保持组织性 每个变更都有自己的文件夹 包含 proposal(提案)、specs(规范)、design(设计)、tasks(任务) 流动迭代 随时更新任何文档 没有僵化的阶段门槛 工具兼容 支持 20+ AI 编程助手(Claude Code、Cursor、Junie、Lingma IDE 等) 2. 安装 2.1 前置要求 Node.js:20.19.0 或更高版本 包管理器:npm、pnpm、yarn 或 bun(任选其一) 检查 Node.js 版本: node --version 如果版本过低,建议使用 nvm 或 fnm 管理 Node.js 版本。 2.2 安装命令 使用 npm 安装: npm install -g @fission-ai/openspec@latest 使用其他包管理器: # pnpm(推荐,速度更快) pnpm add -g @fission-ai/openspec@latest # yarn yarn global add @fission-ai/openspec@latest # bun bun install -g @fission-ai/openspec@latest 2.3 验证安装 # 查看版本号 openspec --version # 查看帮助信息 openspec --help 安装成功后,你将看到类似输出: 1.3.0 2.4 配置 Shell 自动补全(可选) 自 v1.3.0 起,为了避免在某些终端(如 PowerShell)中出现编码问题,Shell 自动补全功能改为手动开启(Opt-in)。 如果你希望在终端中使用 openspec 的命令补全,可以运行以下命令生成并安装补全脚本(支持 bash、zsh、fish 等): # 查看补全命令帮助 openspec completion --help 3. 项目初始化 3.1 初始化命令 openspec init 是 OpenSpec 的入口命令,在项目根目录执行后,它会: 引导选择需要集成的 AI 工具(或使用 --tools 参数跳过交互) 创建 openspec/ 工作目录(含 config.yaml、changes/、specs/) 在所选 AI 工具的对应目录下生成斜杠命令和 Skills 文件 cd your-project openspec init 3.2 交互式配置 openspec init 默认是交互式的,会询问你要配置哪些 AI 工具: ? Which AI tools do you want to configure? (Press <space> to select) ❯◉ Claude Code ◯ Cursor ◯ GitHub Copilot ◯ Cline ◯ Windsurf ... 使用空格键选择,回车键确认。 Qoder 用户提示:如果你使用的是 Qoder IDE,请选择 Qoder。OpenSpec v1.2.0 对 Qoder 提供原生支持,会自动在 .qoder/commands/opsx/ 和 .qoder/skills/ 目录生成对应的命令和 Skills 文件。 3.3 非交互模式 如果需要在脚本或 CI/CD 环境中使用,可以跳过交互式配置: # 跳过所有工具配置 openspec init --tools none # 配置所有支持的 AI 工具 openspec init --tools all # 只配置特定工具(逗号分隔) openspec init --tools claude,cursor # 配置 Qoder openspec init --tools qoder 常用工具标识符列表: 工具名称 --tools 参数值 Claude Code claude Qoder qoder Cursor cursor JetBrains Junie junie Lingma IDE lingma ForgeCode forgecode IBM Bob bob GitHub Copilot github-copilot Cline cline Windsurf windsurf Amazon Q Developer amazon-q Gemini CLI gemini Continue continue Roo Code roocode 完整列表:运行 openspec init --help 可查看当前版本支持的所有工具标识符。 3.4 初始化后的目录结构 your-project/ ├── openspec/ # OpenSpec 工作目录 │ ├── config.yaml # 项目配置(技术栈、约定规则等,注入 AI 请求) │ ├── changes/ # 变更提案目录(每个功能/变更一个文件夹) │ └── specs/ # 主规范目录(已归档的规范) ├── .qoder/ # Qoder 专属目录(示例) │ ├── commands/opsx/ # /opsx 斜杠命令(供 IDE 直接调用) │ │ ├── propose.md │ │ ├── explore.md │ │ ├── apply.md │ │ └── archive.md │ └── skills/ # Agent Skills(AI 自动检测并加载) │ ├── openspec-propose/SKILL.md │ ├── openspec-explore/SKILL.md │ ├── openspec-apply-change/SKILL.md │ └── openspec-archive-change/SKILL.md └── ... (项目其他文件) 注意:openspec init 会根据你选择的 AI 工具,在对应目录生成命令和 Skills 文件。例如,选择 Claude Code 则生成 .claude/commands/opsx/ 和 .claude/skills/,选择 Qoder 则生成 .qoder/commands/opsx/ 和 .qoder/skills/。 3.5 各文件说明 文件/目录 用途 是否必需 config.yaml 项目背景、技术栈、约束条件、每类文档的规则注入 推荐填写 changes/ 存放活跃的变更提案 必需 specs/ 存放已归档的规范 可选 与旧版的区别:v1.0.0 起,openspec/AGENTS.md 和 openspec/project.md 已移除。项目上下文统一写入 openspec/config.yaml 的 context: 字段,该字段会被注入到每一次 AI 规划请求中,比旧方式更可靠。 config.yaml 结构示例: schema: spec-driven context: | Tech stack: TypeScript, React, Node.js Testing: Jest with React Testing Library API: RESTful, documented in docs/api.md We maintain backwards compatibility for all public APIs rules: proposal: - Include rollback plan for risky changes specs: - Use Given/When/Then format for scenarios design: - Include sequence diagrams for complex flows tasks: - Break tasks into max 2-hour chunks 4. 创建变更提案 在 OpenSpec 中,所有的功能开发、Bug 修复、架构变更都以“变更提案(Change)”为单位进行管理。 4.1 创建新变更 方式一:使用斜杠命令(Slash Commands,推荐,一步完成): /opsx:propose <description> 这个命令会: 推断出一个 kebab-case 变更名(如 add-user-auth) 创建 openspec/changes/<name>/ 依次生成 proposal.md、design.md、specs/、tasks.md 所有文档 方式二:仅创建变更目录(扩展工作流 Profile 下使用): 斜杠命令: /opsx:new <change-name> 等价 CLI 命令: openspec new change <change-name> 仅初始化变更目录结构,不创建任何文档;适合配合 /opsx:continue 逐步手动生成文档时使用。 命名建议:使用 kebab-case(短横线分隔),名称应简洁明了地描述变更内容。 # 好的命名示例 add-user-authentication add-payment-module fix-login-timeout # 不好的命名示例 feature1 # 太模糊 addUserAuth # 应使用 kebab-case 4.2 示例:创建 AI Infrastructure CMDB 核心变更 /opsx:propose "实现 AI Infrastructure CMDB 核心功能" AI 将自动创建变更并生成所有规划文档: ✓ Created change directory: openspec/changes/ai-infra-cmdb-core/ ✓ Created proposal.md ✓ Created design.md ✓ Created specs/ directory ✓ specs/accelerator-management/spec.md ✓ Created tasks.md ✓ Created .openspec.yaml Change 'ai-infra-cmdb-core' created successfully! 4.3 变更目录结构详解 openspec/changes/<change-name>/ ├── .openspec.yaml # 变更元数据(ID、状态、创建时间等,由 CLI 自动管理) ├── proposal.md # 提案文档【必填】描述 Why 和 What ├── design.md # 技术设计文档(架构、数据模型、API 设计等) ├── tasks.md # 实现任务清单(按里程碑组织的待办事项) └── specs/ # 规范目录(存放能力规范文件) ├── <capability-1>/ │ └── spec.md # 能力规范(使用 Requirement + Scenario 格式) ├── <capability-2>/ │ └── spec.md 4.4 各文件作用 文件 作用 是否必需 格式要求 proposal.md 说明“为什么做”和“做什么” 必需 必须包含 ## Why 和 ## What Changes(验证器强制检查);推荐包含 ## Capabilities(AI 工作流所需) specs/<capability>/spec.md 详细的需求和验收场景 必需 必须使用 Delta Header + Requirement + Scenario 格式 design.md 技术实现方案 推荐 无严格格式要求 tasks.md 实现任务清单 推荐 无严格格式要求 4.5 变更的生命周期 提案 (斜杠命令) → 编写规范 → 验证 (validate) → 实现 (apply) → 归档 (archive) 提案:/opsx:propose <description>(一步生成所有规划文档) 编写规范:编辑 proposal.md 和 specs/ 验证:openspec validate <name> 实现:/opsx:apply 按照 tasks.md 执行开发 归档:/opsx:archive 将变更中的规范增量(Delta)合并回 openspec/specs/ 主规范目录,并清理 openspec/changes/ 下的临时目录,标志着该功能规范已正式「上线」 5. 文档结构规范 本节详细介绍 proposal.md 和 spec.md 的格式要求。请务必遵循这些格式,否则 openspec validate 会失败。 模板文件:OpenSpec 内置了所有文档模板,可通过 openspec templates 命令查看各模板路径,或直接使用 /opsx:propose / /opsx:new 斜杠命令自动生成完整文档。 5.1 proposal.md - 提案文档 核心要求: proposal.md 必须包含 ## Why 和 ## What Changes 两个验证器强制检查的必需章节;推荐包含 ## Capabilities 章节,作为 AI 自动生成 specs/<name>/spec.md 文件的关键输入。 5.1.1 为什么需要这些章节? OpenSpec 的设计理念是“先想清楚为什么做,再决定做什么,再明确影响哪些能力”: ## Why - 说明变更的背景、问题和动机(验证器强制检查) ## What Changes - 说明具体要添加、修改或删除什么(验证器强制检查) ## Capabilities - 列出 New / Modified Capabilities,驱动 specs/<name>/spec.md 文件的生成(推荐,AI 工作流所需) 5.1.2 完整格式模板 内置模板路径可通过 openspec templates 命令查看;/opsx:propose 斜杠命令会自动生成填充好的完整提案。 必需章节结构: proposal.md 结构: ├── ## Why 【必需 - 验证器强制检查】 │ ├── ### Background(背景) │ ├── ### Problem Statement(问题描述) │ └── ### Alternatives Considered(备选方案) ├── ## What Changes 【必需 - 验证器强制检查】 │ ├── ### New Resources Added(新增资源) │ └── ### New Capabilities(功能点简述,自然语言概括即可) ├── ## Capabilities 【推荐 - AI 工作流所需,驱动 spec 文件生成】 │ ├── ### New Capabilities(kebab-case 标识符列表,每项对应 specs/<name>/ 目录) │ └── ### Modified Capabilities(已有能力的 requirement 变更) ├── ## Impact(影响范围) ├── ## Scope(范围,可选) │ ├── ### In Scope │ └── ### Out of Scope ├── ## Goals(成功标准,可选) └── ## References(参考链接,可选) 注意:章节标题必须完全匹配 ## Why 和 ## What Changes(区分大小写)。 5.2 specs/ 目录 - 能力规范 核心要求: specs/ 必须使用能力文件夹(capability folders),每个能力一个文件夹。 目录结构示例 specs/ ├── accelerator-management/ # 能力一:加速器管理 │ └── spec.md ├── training-job-lifecycle/ # 能力二:训练任务生命周期 │ └── spec.md ├── inference-service/ # 能力三:推理服务 │ └── spec.md └── relationship-management/ # 能力四:关系管理 └── spec.md 重要规则: 不要在 specs/ 根目录直接放置 spec.md 文件 每个能力文件夹名称使用 kebab-case 文件夹名称应体现能力领域 5.3 spec.md - 能力规范格式 核心要求: 必须使用 Delta Header + Requirement + Scenario 格式。 5.3.1 格式要点速查表 元素 格式 示例 Delta Header ## ADDED/MODIFIED/REMOVED Requirements ## ADDED Requirements 需求标题 ### Requirement: <标题> ### Requirement: GPU 自动发现 场景标题 #### Scenario: <标题> #### Scenario: NVIDIA GPU 发现 场景内容 Gherkin 格式 Given/When/Then Delta Header 选择说明: Delta Header 适用场景 ## ADDED Requirements 本次变更新增的能力或需求 ## MODIFIED Requirements 对已有规范中某个 Requirement 的修改 ## REMOVED Requirements 明确废弃或删除的需求 5.3.2 完整格式模板 内置模板路径可通过 openspec templates 查看。 必需格式结构: spec.md 结构: ├── # 能力名称 ├── ## Overview(概述,推荐) │ - 能力简介 │ - 解决的问题 └── ## ADDED/MODIFIED/REMOVED Requirements 【必需】 ├── ### Requirement: <标题> │ ├── **Priority**: P0/P1/P2 │ ├── **Rationale**: ... │ └── #### Scenario: <标题> │ └── Given/When/Then 5.3.3 正确示例 以下示例展示核心 Requirement + Scenario 结构。完整示例(含 ## Overview 段落)参见 examples/openspec/changes/v1-mvp/specs/domain-model/spec.md(电商领域模型规范): ## ADDED Requirements ### Requirement: 商品实体定义 系统 SHALL 定义商品实体,包含唯一标识、名称、价格和库存。 **Priority**: P0 (Critical) **Rationale**: 商品是电商系统的核心实体,是所有交易的基础。 #### Scenario: 创建有效商品 Given 需要创建新商品 When 提供商品信息 { id, name, priceCents, stock } Then 商品实体创建成功 And id 格式为 prod_xxxx And priceCents >= 0 And stock >= 0 5.3.4 常见错误示例 ❌ 错误示例: ## ADDED Requirements ### REQ-001: GPU Discovery # 错误:使用了自定义编号 System SHALL discover GPUs. #### Scenario: Discovery # 错误:场景标题太模糊 ✅ 正确写法: ## ADDED Requirements ### Requirement: GPU 自动发现 # 正确:使用标准格式 系统应自动发现集群中的 GPU 设备。 **Priority**: P0 (Critical) **Rationale**: 核心功能需求。 #### Scenario: NVIDIA GPU 发现 # 正确:场景标题具体 Given 一个包含 NVIDIA GPU 节点的 Kubernetes 集群 When 发现代理部署到集群 Then 所有 NVIDIA GPU 被枚举并记录到 CMDB 5.4 design.md - 技术设计 技术设计文档没有严格的格式要求,但建议包含以下章节。 内置模板路径可通过 openspec templates 查看。 建议章节结构: 章节名称 建议内容 Architecture Overview 系统整体架构图(建议使用 Mermaid 或 ASCII 图)及层次关系说明 Core Components 核心模块列表,每个模块的职责、边界和内部实现要点 Data Model 关键实体的字段定义、类型、约束及实体间关系 API Design 接口路由、请求/响应格式、错误码规范 Integration Patterns 与外部系统/模块的集成方式,包括事件、队列、同步调用等 Technology Stack 所选技术及库、选型理由和备选方案对比 Security 身份认证、权限控制、数据加密、输入校验等安全设计要点 Deployment 环境要求、部署步骤、回滚方案 5.5 tasks.md - 任务清单 任务清单用于将设计拆解为可执行的实现步骤。建议按里程碑组织,使用 GitHub 风格的 Markdown 任务列表,以便在 IDE 中直接勾选。 内置模板路径可通过 openspec templates 查看。 建议章节结构: Milestone:按里程碑对实现步骤分组(如 M1 基础层、M2 API 层、M3 测试)。每个任务拆小,确保单个任务可在 2 小时内完成。 Definition of Done:列出此里程碑的完成标准,如代码通过 CI、测试覆盖率达标、spec validate 通过等。 Progress Tracking:利用 - / - 标记完成进度,方便 IDE 内直观查看。 示例: ## Milestone 1 - Domain Model ### Definition of Done - 完成所有 P0 Requirement 的实现 - `openspec validate v1-mvp` 验证通过 - 单元测试覆盖所有领域实体 ### Tasks - 定义 Product 实体类型(id、name、priceCents、stock) - 定义 Cart / CartItem 实体类型 - 定义 Order / OrderItem 实体类型 - 实现领域实体的编排验证逻辑 ## Milestone 2 - Service Layer ### Definition of Done - 所有服务方法均有对应集成测试 ### Tasks - 实现 CatalogService.getProduct / listProducts - 实现 CartService.addItem / removeItem - 实现 OrderService.checkout 5.6 格式速查 proposal.md 必需章节: ├── ## Why 【必需 - 验证器强制检查】 │ ├── ### Background │ ├── ### Problem Statement │ └── ### Alternatives Considered ├── ## What Changes 【必需 - 验证器强制检查】 │ ├── ### New Resources Added │ └── ### New Capabilities └── ## Capabilities 【推荐 - AI 工作流所需,驱动 spec 文件生成】 ├── ### New Capabilities └── ### Modified Capabilities specs//spec.md 必需格式: ├── # 能力名称 ├── ## Overview(推荐) └── ## ADDED/MODIFIED/REMOVED Requirements 【必需】 ├── ### Requirement: <标题> │ ├── **Priority**: P0/P1/P2 │ ├── **Rationale**: ... │ └── #### Scenario: <标题> │ └── Given/When/Then 5.7 模板文件汇总 模板 对应内置文件(通过 openspec templates 查看完整路径) 用途 proposal.md 模板 schemas/spec-driven/templates/proposal.md 提案文档模板 spec.md 模板 schemas/spec-driven/templates/spec.md 能力规范模板 design.md 模板 schemas/spec-driven/templates/design.md 技术设计模板 tasks.md 模板 schemas/spec-driven/templates/tasks.md 任务清单模板 6. 验证与常见错误 6.1 验证命令 完成文档编写后,使用验证命令检查格式是否正确: openspec validate <change-name> 验证成功时显示: Change '<change-name>' is valid 验证失败时会显示具体错误信息。 6.2 常见错误及解决方案 6.2.1 错误 1:未找到任何 Delta 错误信息: ✗ file: Change must have at least one delta. No deltas found. Ensure your change has a specs/ directory with capability folders (e.g. specs/http-server/spec.md) containing .md files that use delta headers (## ADDED/MODIFIED/REMOVED/RENAMED Requirements) and that each requirement includes at least one "#### Scenario:" block. Tip: run "openspec change show <change-id> --json --deltas-only" to inspect parsed deltas. 原因:specs/ 目录结构不正确,或者缺少有效的 Delta Header。 解决方案: 确保 specs/ 下有能力文件夹: specs/ └── your-capability/ # 能力文件夹 └── spec.md # 规范文件 确保 spec.md 中有 Delta Header: ## ADDED Requirements ### Requirement: 某个需求 ... 常见错误: specs/ └── spec.md # ❌ 错误:直接放在 specs/ 根目录 6.2.2 错误 2:需求条目解析失败 错误信息: ✗ cap1/spec.md: Delta sections ## ADDED Requirements were found, but no requirement entries parsed. Ensure each section includes at least one "### Requirement:" block (REMOVED may use bullet list syntax). 原因:需求标题格式不正确。 错误示例: ## ADDED Requirements ### REQ-001: GPU Discovery # ❌ 错误:使用了自定义编号 ### GPU Discovery # ❌ 错误:缺少 "Requirement:" 前缀 ### requirement: GPU Discovery # ❌ 错误:"requirement" 应首字母大写 正确格式: ## ADDED Requirements ### Requirement: GPU 自动发现 # ✓ 正确格式 6.2.3 错误 3:缺少场景块 错误信息: ✗ cap1/spec.md: ADDED "test" must include at least one scenario 原因:每个需求必须至少有一个场景。 错误示例: ### Requirement: GPU 自动发现 系统应自动发现 GPU 设备。 # ❌ 没有场景块 正确格式: ### Requirement: GPU 自动发现 系统应自动发现 GPU 设备。 **Priority**: P0 (Critical) **Rationale**: 核心功能需求。 #### Scenario: NVIDIA GPU 发现 Given 一个包含 NVIDIA GPU 节点的 Kubernetes 集群 When 发现代理部署到集群 Then 所有 NVIDIA GPU 被枚举并记录到 CMDB 6.3 调试技巧 6.3.1 查看 Delta 解析结果 如果验证失败但不确定原因,可以查看解析后的结构: openspec show <change-name> --json --deltas-only 这会输出 JSON 格式的解析结果,帮助你了解 OpenSpec 是如何解析你的文档的。 6.3.2 查看变更状态 openspec status --change <change-name> 提示:自 v1.3.0 起,如果当前不存在任何变更,openspec status 命令会优雅地退出(提示无变更),而不再抛出致命错误。 输出示例: Change: ai-infra-cmdb-core Schema: spec-driven Progress: 1/4 artifacts complete proposal design specs tasks (blocked by: design, specs) 6.3.3 验证检查清单 在运行 openspec validate 之前,请确认: proposal.md 包含 ## Why 章节 proposal.md 包含 ## What Changes 章节 specs/ 下有能力文件夹(不是直接的 spec.md) 每个 spec.md 包含 Delta Header(## ADDED/MODIFIED/REMOVED Requirements) 每个需求使用 ### Requirement: <标题> 格式 每个需求至少有一个 #### Scenario: <标题> 块 每个 Scenario 使用 Gherkin 格式(Given/When/Then) 7. 常用命令参考 7.1 初始化与创建 命令 说明 示例 openspec init 初始化 OpenSpec 项目 openspec init --tools qoder openspec new change <name> 仅创建变更目录结构 openspec new change add-user-auth openspec update 更新 AI 技能和命令文件 openspec update 7.2 查看与验证 命令 说明 示例 openspec view 打开终端交互界面 openspec view openspec status --change <name> 查看变更状态 openspec status --change user-auth openspec validate <name> 验证变更文档格式 openspec validate user-auth openspec list --changes 列出所有变更 openspec list --changes openspec list --specs 列出所有规范 openspec list --specs openspec show <name> 显示变更详情 openspec show user-auth --json --deltas-only 7.3 归档与管理 命令 说明 示例 openspec archive <name> 归档已完成的变更(将 Delta 合并至 specs/ 主目录并清理 changes/ 临时目录) openspec archive user-auth 7.4 配置与调试 命令 说明 示例 openspec config list 查看当前配置 openspec config list openspec config profile 设置工作流 Profile openspec config profile openspec templates 查看内置文档模板的绝对路径 openspec templates openspec schemas 列出可用 Schema openspec schemas openspec --version 查看版本号 openspec --version openspec --help 查看帮助信息 openspec --help 7.5 全局选项 openspec <command> 选项: -V, --version 显示版本号 -h, --help 显示帮助信息 --no-color 禁用彩色输出 注意:--json 是各命令的独立选项,不是全局选项。例如 openspec show <name> --json 或 openspec validate --json。 7.6 命令速查 常用命令快速参考: # 初始化项目 openspec init --tools none # 创建变更目录(仅创建目录,不生成文档) openspec new change <name> # 列出所有变更 / 规范 openspec list --changes openspec list --specs # 验证变更 openspec validate <name> # 查看状态 openspec status --change <name> # 归档变更 openspec archive <name> # 更新工具文件 openspec update 8. 最佳实践 8.1 提案编写最佳实践 8.1.1 推荐做法 先写 Why 再写 What:先说明为什么需要这个变更,再说明具体改什么 保持简洁:proposal.md 应该是高层次的概述,详细内容放在 specs/ 中 明确范围:清楚说明 In Scope 和 Out of Scope 提供背景:让 AI 和团队成员都能理解上下文 8.1.2 避免的做法 在 proposal.md 中写详细的 API 定义(应放在 specs/ 或 design.md) 使用模糊的描述如"优化性能"、"改进体验"(应具体说明目标和指标) 忽略 Alternatives Considered 章节(说明为什么选择当前方案很重要) 8.1.3 示例对比 ❌ 不好的 Why 章节: ## Why 我们需要添加用户认证功能。 ✅ 好的 Why 章节: ## Why ### Background 当前系统没有用户认证功能,任何人都可以访问所有数据和功能。 这导致: - 无法追踪操作日志的责任人 - 敏感数据缺乏保护 - 无法实现细粒度的权限控制 ### Problem Statement 系统需要一个安全可靠的用户认证机制,支持: - 用户名密码登录 - 第三方 OAuth 登录(GitHub、Google) - 会话管理和安全退出 ### Alternatives Considered 1. **自建认证系统**:完全控制,但开发维护成本高 2. **使用 Auth0**:功能完善,但费用较高 3. **使用 Keycloak**:开源免费,支持多种协议 ✓ 已选择此方案 8.2 规范编写最佳实践 8.2.1 推荐做法 一个能力一个文件夹:按功能领域划分能力 需求粒度适中:每个需求应该是可测试的单一功能点 场景具体化:使用具体的 Gherkin 场景描述行为 优先级标注:为每个需求标注 P0/P1/P2 优先级 添加 Rationale:说明为什么需要这个需求 8.2.2 避免的做法 在一个 spec.md 中放多个不相关的能力 需求过于宽泛(如"系统应该快") 场景太模糊(如"系统应该工作") 8.3 场景编写最佳实践 8.3.1 Gherkin 格式要点 关键字 用途 示例 Given 前置条件,描述系统初始状态 Given 用户已登录系统 When 触发动作 When 用户点击"提交订单"按钮 Then 预期结果 Then 订单状态变为"待支付" And 连接多个条件或结果 And 用户收到订单确认邮件 8.3.2 好的场景示例 Scenario: 使用信用卡支付订单 Given 用户已登录系统 And 购物车中有 2 件商品,总价 299 元 And 用户已绑定信用卡 When 用户选择"信用卡支付"并确认 Then 订单创建成功 And 从信用卡扣除 299 元 And 用户收到支付成功通知 And 库存减少 2 件 8.3.3 不好的场景示例 Scenario: 支付 Given 系统 When 支付 Then 成功 问题: 太模糊,无法验证 缺少具体的前置条件 没有明确的预期结果 8.4 迭代开发最佳实践 增量添加:可以随时添加新的需求到变更中 频繁验证:使用 openspec validate 确保格式正确 版本控制:将 OpenSpec 文档纳入 Git 管理 及时归档:完成开发后使用 openspec archive 归档变更 存量项目(Brownfield)优先从小处入手:对于已有历史代码的项目,建议从一个小的、相对独立的功能开始创建第一个 Change,逐步建立规范体系,不要试图一次性为所有旧代码补规范 8.5 与 AI 协作最佳实践 8.5.1 OPSX 斜杠命令(Slash Commands,推荐) OpenSpec 1.0+ 引入了全新的 OPSX 工作流,替换了旧版的阶段锁定模式。所有命令均通过 openspec init 安装到 AI 工具对应目录。 默认 Core 配置(常用 4 个命令): 命令 作用 /opsx:propose <description> 一步创建变更并智能生成所有规划文档(AI 基于描述自动推断 kebab-case 目录名并填充 proposal/design/specs/tasks) /opsx:explore 进入探索模式,思考问题、调查代码库,不写代码 /opsx:apply 按照 tasks.md 实现任务 /opsx:archive 完成并归档当前变更 扩展工作流命令(通过 openspec config profile 开启) 命令 作用 /opsx:new 仅初始化变更目录结构,不创建文档 /opsx:continue 按依赖顺序创建下一个文档(逐步模式) /opsx:ff 快进生成所有规划文档(一步到位) /opsx:verify 验证实现是否与规范一致 /opsx:sync 将 Delta Spec 合并到主规范(不归档) /opsx:bulk-archive 批量归档多个已完成的变更 /opsx:onboard 带教 15 分钟全流程引导,适合新手上手 迁移说明:旧版命令(/openspec:proposal、/openspec:apply、/openspec:archive)已在 v1.0.0 移除。修复映射关系: /openspec:proposal → /opsx:propose /openspec:apply → /opsx:apply /openspec:archive → /opsx:archive 8.5.2 与 AI 协作的技巧 先探索后提案:不确定时先用 /opsx:explore 思考,明确后再 /opsx:propose 支持流动迭代:实现过程发现设计错误?直接编辑对应文档即可,无阶段锁定 定期清理对话上下文:开始实现任务前,建议清空当前对话上下文,确保高质量的指令注入效果 增量迭代:完成一个需求后验证,再进行下一个 8.6 团队协作最佳实践 8.6.1 代码审查清单 在 PR 审查时,检查 OpenSpec 文档: proposal.md 有清晰的 Why 和 What 每个 Requirement 都有至少一个 Scenario Scenario 使用标准的 Gherkin 格式 优先级标注合理 没有遗漏重要的边界场景 8.6.2 文档维护 保持更新:实现过程中如果发现规范需要调整,及时更新文档 同步修改:如果需求变更,先更新 spec.md 再修改代码 归档记录:归档的变更应保留历史记录,便于追溯 9. 附录 9.1 支持的 AI 工具 OpenSpec 支持 20+ AI 编程助手,以下是常用工具: 工具 类型 支持程度 Claude Code CLI + IDE 完全支持 Qoder IDE 完全支持 Cursor IDE 完全支持 JetBrains Junie IDE 插件 完全支持 Lingma IDE IDE 插件 完全支持 ForgeCode IDE 插件 完全支持 IBM Bob IDE 插件 完全支持 GitHub Copilot IDE 插件 完全支持 Cline VS Code 插件 完全支持 Windsurf IDE 完全支持 Amazon Q Developer IDE 插件 完全支持 Gemini CLI CLI 完全支持 Continue IDE 插件 完全支持 Aider CLI 支持(命令行工具,不支持 openspec init 自动生成指令) Roo Code VS Code 插件 完全支持 9.2 遥测设置 OpenSpec 收集匿名使用统计数据,用于改进产品。如需禁用: # 方法一:设置环境变量 export OPENSPEC_TELEMETRY=0 # 方法二:使用通用遥测禁用标志 export DO_NOT_TRACK=1 # 方法三:在 shell 配置文件中永久设置 echo 'export OPENSPEC_TELEMETRY=0' >> ~/.zshrc # Zsh echo 'export OPENSPEC_TELEMETRY=0' >> ~/.bashrc # Bash 9.3 常见问题 (FAQ) 9.3.1 Q1:OpenSpec 与 Swagger/OpenAPI 有什么区别? 特性 OpenSpec OpenAPI/Swagger 主要用途 需求规范驱动开发 API 接口文档 文档类型 Markdown YAML/JSON 验证方式 CLI 验证 + AI 理解 语法验证 适用阶段 开发前期(需求定义) 开发中期(接口定义) 目标用户 产品经理 + 开发者 + AI 开发者 + 前端 两者可以配合使用:先用 OpenSpec 定义需求和场景,再用 OpenAPI 定义接口细节。 9.3.2 Q2:已有的项目如何引入 OpenSpec? 在项目根目录运行 openspec init --tools none 为下一个功能创建变更提案 逐步建立规范体系,不需要一次性覆盖所有功能 9.3.3 Q3:规范写完后,AI 不遵循怎么办? 运行 openspec update 刷新 Skills 和命令文件 重启 IDE 使斜杠命令生效 在 openspec/config.yaml 的 rules: 字段添加具体约束条件 使用 /opsx:apply 让 AI 从任务清单开始实现,而不是直接要求写代码 9.3.4 Q4:多个变更可以同时进行吗? 可以。每个变更都是独立的文件夹,可以并行开发。但建议: 变更之间避免依赖关系 完成一个变更后再创建下一个 9.4 参考链接 资源 链接 官方仓库 https://github.com/Fission-AI/OpenSpec 快速入门 https://openspec.pro/getting-started/ 官方文档 https://github.com/Fission-AI/OpenSpec/tree/main/docs npm 包 https://www.npmjs.com/package/@fission-ai/openspec 配套幻灯片(旧版) openspec-user-manual-v1.pptx 配套幻灯片(当前版) openspec-user-manual-v2.pptx 文档版本: 2.1 最后更新: 2026-04-13 基于 OpenSpec v1.3.0 更新(支持新 IDE、Shell completions 优化等)
OpenSpec 使用手册 OpenSpec 使用手册 基于项目的实践经验总结。 1. 简介 OpenSpec 是一个规范驱动开发(Spec-Driven Development, SDD)框架,专为 AI 编程助手设计。它通过在编写代码之前先定义规范,确保人与 AI 对需求达成一致。 1.1 什么是规范驱动开发? 传统开发流程通常是:需求 → 直接编码 → 测试 → 交付。 规范驱动开发的流程是:需求 → 编写规范 → 验证规范 → 编码实现。 这种方式的优势在于: 人与 AI 先就"做什么"达成一致,避免返工 规范文档作为契约,减少沟通成本 规范可以版本化管理,便于追溯 1.2 核心理念 理念 含义 流动而非僵化 文档可以随时更新,没有严格的阶段门槛 迭代而非瀑布 支持增量添加需求,逐步完善 简单而非复杂 只需要 Markdown 文件,无复杂工具链 兼顾存量与新建项目 既适用于已有代码库(Brownfield),也适用于全新项目(Greenfield) 术语解释: Brownfield(存量项目):指已经存在的、有历史代码的项目。OpenSpec 可以逐步引入,不必重构现有代码。 Greenfield(新建项目):指从零开始的新项目。OpenSpec 可以从一开始就建立规范体系。 1.3 核心价值 先达成一致再构建 在编写代码之前,人与 AI 先就规范达成共识 避免 AI 理解偏差导致的返工 保持组织性 每个变更都有自己的文件夹 包含 proposal(提案)、specs(规范)、design(设计)、tasks(任务) 流动迭代 随时更新任何文档 没有僵化的阶段门槛 工具兼容 支持 20+ AI 编程助手(Claude Code、Cursor、Junie、Lingma IDE 等) 2. 安装 2.1 前置要求 Node.js:20.19.0 或更高版本 包管理器:npm、pnpm、yarn 或 bun(任选其一) 检查 Node.js 版本: node --version 如果版本过低,建议使用 nvm 或 fnm 管理 Node.js 版本。 2.2 安装命令 使用 npm 安装: npm install -g @fission-ai/openspec@latest 使用其他包管理器: # pnpm(推荐,速度更快) pnpm add -g @fission-ai/openspec@latest # yarn yarn global add @fission-ai/openspec@latest # bun bun install -g @fission-ai/openspec@latest 2.3 验证安装 # 查看版本号 openspec --version # 查看帮助信息 openspec --help 安装成功后,你将看到类似输出: 1.3.0 2.4 配置 Shell 自动补全(可选) 自 v1.3.0 起,为了避免在某些终端(如 PowerShell)中出现编码问题,Shell 自动补全功能改为手动开启(Opt-in)。 如果你希望在终端中使用 openspec 的命令补全,可以运行以下命令生成并安装补全脚本(支持 bash、zsh、fish 等): # 查看补全命令帮助 openspec completion --help 3. 项目初始化 3.1 初始化命令 openspec init 是 OpenSpec 的入口命令,在项目根目录执行后,它会: 引导选择需要集成的 AI 工具(或使用 --tools 参数跳过交互) 创建 openspec/ 工作目录(含 config.yaml、changes/、specs/) 在所选 AI 工具的对应目录下生成斜杠命令和 Skills 文件 cd your-project openspec init 3.2 交互式配置 openspec init 默认是交互式的,会询问你要配置哪些 AI 工具: ? Which AI tools do you want to configure? (Press <space> to select) ❯◉ Claude Code ◯ Cursor ◯ GitHub Copilot ◯ Cline ◯ Windsurf ... 使用空格键选择,回车键确认。 Qoder 用户提示:如果你使用的是 Qoder IDE,请选择 Qoder。OpenSpec v1.2.0 对 Qoder 提供原生支持,会自动在 .qoder/commands/opsx/ 和 .qoder/skills/ 目录生成对应的命令和 Skills 文件。 3.3 非交互模式 如果需要在脚本或 CI/CD 环境中使用,可以跳过交互式配置: # 跳过所有工具配置 openspec init --tools none # 配置所有支持的 AI 工具 openspec init --tools all # 只配置特定工具(逗号分隔) openspec init --tools claude,cursor # 配置 Qoder openspec init --tools qoder 常用工具标识符列表: 工具名称 --tools 参数值 Claude Code claude Qoder qoder Cursor cursor JetBrains Junie junie Lingma IDE lingma ForgeCode forgecode IBM Bob bob GitHub Copilot github-copilot Cline cline Windsurf windsurf Amazon Q Developer amazon-q Gemini CLI gemini Continue continue Roo Code roocode 完整列表:运行 openspec init --help 可查看当前版本支持的所有工具标识符。 3.4 初始化后的目录结构 your-project/ ├── openspec/ # OpenSpec 工作目录 │ ├── config.yaml # 项目配置(技术栈、约定规则等,注入 AI 请求) │ ├── changes/ # 变更提案目录(每个功能/变更一个文件夹) │ └── specs/ # 主规范目录(已归档的规范) ├── .qoder/ # Qoder 专属目录(示例) │ ├── commands/opsx/ # /opsx 斜杠命令(供 IDE 直接调用) │ │ ├── propose.md │ │ ├── explore.md │ │ ├── apply.md │ │ └── archive.md │ └── skills/ # Agent Skills(AI 自动检测并加载) │ ├── openspec-propose/SKILL.md │ ├── openspec-explore/SKILL.md │ ├── openspec-apply-change/SKILL.md │ └── openspec-archive-change/SKILL.md └── ... (项目其他文件) 注意:openspec init 会根据你选择的 AI 工具,在对应目录生成命令和 Skills 文件。例如,选择 Claude Code 则生成 .claude/commands/opsx/ 和 .claude/skills/,选择 Qoder 则生成 .qoder/commands/opsx/ 和 .qoder/skills/。 3.5 各文件说明 文件/目录 用途 是否必需 config.yaml 项目背景、技术栈、约束条件、每类文档的规则注入 推荐填写 changes/ 存放活跃的变更提案 必需 specs/ 存放已归档的规范 可选 与旧版的区别:v1.0.0 起,openspec/AGENTS.md 和 openspec/project.md 已移除。项目上下文统一写入 openspec/config.yaml 的 context: 字段,该字段会被注入到每一次 AI 规划请求中,比旧方式更可靠。 config.yaml 结构示例: schema: spec-driven context: | Tech stack: TypeScript, React, Node.js Testing: Jest with React Testing Library API: RESTful, documented in docs/api.md We maintain backwards compatibility for all public APIs rules: proposal: - Include rollback plan for risky changes specs: - Use Given/When/Then format for scenarios design: - Include sequence diagrams for complex flows tasks: - Break tasks into max 2-hour chunks 4. 创建变更提案 在 OpenSpec 中,所有的功能开发、Bug 修复、架构变更都以“变更提案(Change)”为单位进行管理。 4.1 创建新变更 方式一:使用斜杠命令(Slash Commands,推荐,一步完成): /opsx:propose <description> 这个命令会: 推断出一个 kebab-case 变更名(如 add-user-auth) 创建 openspec/changes/<name>/ 依次生成 proposal.md、design.md、specs/、tasks.md 所有文档 方式二:仅创建变更目录(扩展工作流 Profile 下使用): 斜杠命令: /opsx:new <change-name> 等价 CLI 命令: openspec new change <change-name> 仅初始化变更目录结构,不创建任何文档;适合配合 /opsx:continue 逐步手动生成文档时使用。 命名建议:使用 kebab-case(短横线分隔),名称应简洁明了地描述变更内容。 # 好的命名示例 add-user-authentication add-payment-module fix-login-timeout # 不好的命名示例 feature1 # 太模糊 addUserAuth # 应使用 kebab-case 4.2 示例:创建 AI Infrastructure CMDB 核心变更 /opsx:propose "实现 AI Infrastructure CMDB 核心功能" AI 将自动创建变更并生成所有规划文档: ✓ Created change directory: openspec/changes/ai-infra-cmdb-core/ ✓ Created proposal.md ✓ Created design.md ✓ Created specs/ directory ✓ specs/accelerator-management/spec.md ✓ Created tasks.md ✓ Created .openspec.yaml Change 'ai-infra-cmdb-core' created successfully! 4.3 变更目录结构详解 openspec/changes/<change-name>/ ├── .openspec.yaml # 变更元数据(ID、状态、创建时间等,由 CLI 自动管理) ├── proposal.md # 提案文档【必填】描述 Why 和 What ├── design.md # 技术设计文档(架构、数据模型、API 设计等) ├── tasks.md # 实现任务清单(按里程碑组织的待办事项) └── specs/ # 规范目录(存放能力规范文件) ├── <capability-1>/ │ └── spec.md # 能力规范(使用 Requirement + Scenario 格式) ├── <capability-2>/ │ └── spec.md 4.4 各文件作用 文件 作用 是否必需 格式要求 proposal.md 说明“为什么做”和“做什么” 必需 必须包含 ## Why 和 ## What Changes(验证器强制检查);推荐包含 ## Capabilities(AI 工作流所需) specs/<capability>/spec.md 详细的需求和验收场景 必需 必须使用 Delta Header + Requirement + Scenario 格式 design.md 技术实现方案 推荐 无严格格式要求 tasks.md 实现任务清单 推荐 无严格格式要求 4.5 变更的生命周期 提案 (斜杠命令) → 编写规范 → 验证 (validate) → 实现 (apply) → 归档 (archive) 提案:/opsx:propose <description>(一步生成所有规划文档) 编写规范:编辑 proposal.md 和 specs/ 验证:openspec validate <name> 实现:/opsx:apply 按照 tasks.md 执行开发 归档:/opsx:archive 将变更中的规范增量(Delta)合并回 openspec/specs/ 主规范目录,并清理 openspec/changes/ 下的临时目录,标志着该功能规范已正式「上线」 5. 文档结构规范 本节详细介绍 proposal.md 和 spec.md 的格式要求。请务必遵循这些格式,否则 openspec validate 会失败。 模板文件:OpenSpec 内置了所有文档模板,可通过 openspec templates 命令查看各模板路径,或直接使用 /opsx:propose / /opsx:new 斜杠命令自动生成完整文档。 5.1 proposal.md - 提案文档 核心要求: proposal.md 必须包含 ## Why 和 ## What Changes 两个验证器强制检查的必需章节;推荐包含 ## Capabilities 章节,作为 AI 自动生成 specs/<name>/spec.md 文件的关键输入。 5.1.1 为什么需要这些章节? OpenSpec 的设计理念是“先想清楚为什么做,再决定做什么,再明确影响哪些能力”: ## Why - 说明变更的背景、问题和动机(验证器强制检查) ## What Changes - 说明具体要添加、修改或删除什么(验证器强制检查) ## Capabilities - 列出 New / Modified Capabilities,驱动 specs/<name>/spec.md 文件的生成(推荐,AI 工作流所需) 5.1.2 完整格式模板 内置模板路径可通过 openspec templates 命令查看;/opsx:propose 斜杠命令会自动生成填充好的完整提案。 必需章节结构: proposal.md 结构: ├── ## Why 【必需 - 验证器强制检查】 │ ├── ### Background(背景) │ ├── ### Problem Statement(问题描述) │ └── ### Alternatives Considered(备选方案) ├── ## What Changes 【必需 - 验证器强制检查】 │ ├── ### New Resources Added(新增资源) │ └── ### New Capabilities(功能点简述,自然语言概括即可) ├── ## Capabilities 【推荐 - AI 工作流所需,驱动 spec 文件生成】 │ ├── ### New Capabilities(kebab-case 标识符列表,每项对应 specs/<name>/ 目录) │ └── ### Modified Capabilities(已有能力的 requirement 变更) ├── ## Impact(影响范围) ├── ## Scope(范围,可选) │ ├── ### In Scope │ └── ### Out of Scope ├── ## Goals(成功标准,可选) └── ## References(参考链接,可选) 注意:章节标题必须完全匹配 ## Why 和 ## What Changes(区分大小写)。 5.2 specs/ 目录 - 能力规范 核心要求: specs/ 必须使用能力文件夹(capability folders),每个能力一个文件夹。 目录结构示例 specs/ ├── accelerator-management/ # 能力一:加速器管理 │ └── spec.md ├── training-job-lifecycle/ # 能力二:训练任务生命周期 │ └── spec.md ├── inference-service/ # 能力三:推理服务 │ └── spec.md └── relationship-management/ # 能力四:关系管理 └── spec.md 重要规则: 不要在 specs/ 根目录直接放置 spec.md 文件 每个能力文件夹名称使用 kebab-case 文件夹名称应体现能力领域 5.3 spec.md - 能力规范格式 核心要求: 必须使用 Delta Header + Requirement + Scenario 格式。 5.3.1 格式要点速查表 元素 格式 示例 Delta Header ## ADDED/MODIFIED/REMOVED Requirements ## ADDED Requirements 需求标题 ### Requirement: <标题> ### Requirement: GPU 自动发现 场景标题 #### Scenario: <标题> #### Scenario: NVIDIA GPU 发现 场景内容 Gherkin 格式 Given/When/Then Delta Header 选择说明: Delta Header 适用场景 ## ADDED Requirements 本次变更新增的能力或需求 ## MODIFIED Requirements 对已有规范中某个 Requirement 的修改 ## REMOVED Requirements 明确废弃或删除的需求 5.3.2 完整格式模板 内置模板路径可通过 openspec templates 查看。 必需格式结构: spec.md 结构: ├── # 能力名称 ├── ## Overview(概述,推荐) │ - 能力简介 │ - 解决的问题 └── ## ADDED/MODIFIED/REMOVED Requirements 【必需】 ├── ### Requirement: <标题> │ ├── **Priority**: P0/P1/P2 │ ├── **Rationale**: ... │ └── #### Scenario: <标题> │ └── Given/When/Then 5.3.3 正确示例 以下示例展示核心 Requirement + Scenario 结构。完整示例(含 ## Overview 段落)参见 examples/openspec/changes/v1-mvp/specs/domain-model/spec.md(电商领域模型规范): ## ADDED Requirements ### Requirement: 商品实体定义 系统 SHALL 定义商品实体,包含唯一标识、名称、价格和库存。 **Priority**: P0 (Critical) **Rationale**: 商品是电商系统的核心实体,是所有交易的基础。 #### Scenario: 创建有效商品 Given 需要创建新商品 When 提供商品信息 { id, name, priceCents, stock } Then 商品实体创建成功 And id 格式为 prod_xxxx And priceCents >= 0 And stock >= 0 5.3.4 常见错误示例 ❌ 错误示例: ## ADDED Requirements ### REQ-001: GPU Discovery # 错误:使用了自定义编号 System SHALL discover GPUs. #### Scenario: Discovery # 错误:场景标题太模糊 ✅ 正确写法: ## ADDED Requirements ### Requirement: GPU 自动发现 # 正确:使用标准格式 系统应自动发现集群中的 GPU 设备。 **Priority**: P0 (Critical) **Rationale**: 核心功能需求。 #### Scenario: NVIDIA GPU 发现 # 正确:场景标题具体 Given 一个包含 NVIDIA GPU 节点的 Kubernetes 集群 When 发现代理部署到集群 Then 所有 NVIDIA GPU 被枚举并记录到 CMDB 5.4 design.md - 技术设计 技术设计文档没有严格的格式要求,但建议包含以下章节。 内置模板路径可通过 openspec templates 查看。 建议章节结构: 章节名称 建议内容 Architecture Overview 系统整体架构图(建议使用 Mermaid 或 ASCII 图)及层次关系说明 Core Components 核心模块列表,每个模块的职责、边界和内部实现要点 Data Model 关键实体的字段定义、类型、约束及实体间关系 API Design 接口路由、请求/响应格式、错误码规范 Integration Patterns 与外部系统/模块的集成方式,包括事件、队列、同步调用等 Technology Stack 所选技术及库、选型理由和备选方案对比 Security 身份认证、权限控制、数据加密、输入校验等安全设计要点 Deployment 环境要求、部署步骤、回滚方案 5.5 tasks.md - 任务清单 任务清单用于将设计拆解为可执行的实现步骤。建议按里程碑组织,使用 GitHub 风格的 Markdown 任务列表,以便在 IDE 中直接勾选。 内置模板路径可通过 openspec templates 查看。 建议章节结构: Milestone:按里程碑对实现步骤分组(如 M1 基础层、M2 API 层、M3 测试)。每个任务拆小,确保单个任务可在 2 小时内完成。 Definition of Done:列出此里程碑的完成标准,如代码通过 CI、测试覆盖率达标、spec validate 通过等。 Progress Tracking:利用 - / - 标记完成进度,方便 IDE 内直观查看。 示例: ## Milestone 1 - Domain Model ### Definition of Done - 完成所有 P0 Requirement 的实现 - `openspec validate v1-mvp` 验证通过 - 单元测试覆盖所有领域实体 ### Tasks - 定义 Product 实体类型(id、name、priceCents、stock) - 定义 Cart / CartItem 实体类型 - 定义 Order / OrderItem 实体类型 - 实现领域实体的编排验证逻辑 ## Milestone 2 - Service Layer ### Definition of Done - 所有服务方法均有对应集成测试 ### Tasks - 实现 CatalogService.getProduct / listProducts - 实现 CartService.addItem / removeItem - 实现 OrderService.checkout 5.6 格式速查 proposal.md 必需章节: ├── ## Why 【必需 - 验证器强制检查】 │ ├── ### Background │ ├── ### Problem Statement │ └── ### Alternatives Considered ├── ## What Changes 【必需 - 验证器强制检查】 │ ├── ### New Resources Added │ └── ### New Capabilities └── ## Capabilities 【推荐 - AI 工作流所需,驱动 spec 文件生成】 ├── ### New Capabilities └── ### Modified Capabilities specs//spec.md 必需格式: ├── # 能力名称 ├── ## Overview(推荐) └── ## ADDED/MODIFIED/REMOVED Requirements 【必需】 ├── ### Requirement: <标题> │ ├── **Priority**: P0/P1/P2 │ ├── **Rationale**: ... │ └── #### Scenario: <标题> │ └── Given/When/Then 5.7 模板文件汇总 模板 对应内置文件(通过 openspec templates 查看完整路径) 用途 proposal.md 模板 schemas/spec-driven/templates/proposal.md 提案文档模板 spec.md 模板 schemas/spec-driven/templates/spec.md 能力规范模板 design.md 模板 schemas/spec-driven/templates/design.md 技术设计模板 tasks.md 模板 schemas/spec-driven/templates/tasks.md 任务清单模板 6. 验证与常见错误 6.1 验证命令 完成文档编写后,使用验证命令检查格式是否正确: openspec validate <change-name> 验证成功时显示: Change '<change-name>' is valid 验证失败时会显示具体错误信息。 6.2 常见错误及解决方案 6.2.1 错误 1:未找到任何 Delta 错误信息: ✗ file: Change must have at least one delta. No deltas found. Ensure your change has a specs/ directory with capability folders (e.g. specs/http-server/spec.md) containing .md files that use delta headers (## ADDED/MODIFIED/REMOVED/RENAMED Requirements) and that each requirement includes at least one "#### Scenario:" block. Tip: run "openspec change show <change-id> --json --deltas-only" to inspect parsed deltas. 原因:specs/ 目录结构不正确,或者缺少有效的 Delta Header。 解决方案: 确保 specs/ 下有能力文件夹: specs/ └── your-capability/ # 能力文件夹 └── spec.md # 规范文件 确保 spec.md 中有 Delta Header: ## ADDED Requirements ### Requirement: 某个需求 ... 常见错误: specs/ └── spec.md # ❌ 错误:直接放在 specs/ 根目录 6.2.2 错误 2:需求条目解析失败 错误信息: ✗ cap1/spec.md: Delta sections ## ADDED Requirements were found, but no requirement entries parsed. Ensure each section includes at least one "### Requirement:" block (REMOVED may use bullet list syntax). 原因:需求标题格式不正确。 错误示例: ## ADDED Requirements ### REQ-001: GPU Discovery # ❌ 错误:使用了自定义编号 ### GPU Discovery # ❌ 错误:缺少 "Requirement:" 前缀 ### requirement: GPU Discovery # ❌ 错误:"requirement" 应首字母大写 正确格式: ## ADDED Requirements ### Requirement: GPU 自动发现 # ✓ 正确格式 6.2.3 错误 3:缺少场景块 错误信息: ✗ cap1/spec.md: ADDED "test" must include at least one scenario 原因:每个需求必须至少有一个场景。 错误示例: ### Requirement: GPU 自动发现 系统应自动发现 GPU 设备。 # ❌ 没有场景块 正确格式: ### Requirement: GPU 自动发现 系统应自动发现 GPU 设备。 **Priority**: P0 (Critical) **Rationale**: 核心功能需求。 #### Scenario: NVIDIA GPU 发现 Given 一个包含 NVIDIA GPU 节点的 Kubernetes 集群 When 发现代理部署到集群 Then 所有 NVIDIA GPU 被枚举并记录到 CMDB 6.3 调试技巧 6.3.1 查看 Delta 解析结果 如果验证失败但不确定原因,可以查看解析后的结构: openspec show <change-name> --json --deltas-only 这会输出 JSON 格式的解析结果,帮助你了解 OpenSpec 是如何解析你的文档的。 6.3.2 查看变更状态 openspec status --change <change-name> 提示:自 v1.3.0 起,如果当前不存在任何变更,openspec status 命令会优雅地退出(提示无变更),而不再抛出致命错误。 输出示例: Change: ai-infra-cmdb-core Schema: spec-driven Progress: 1/4 artifacts complete proposal design specs tasks (blocked by: design, specs) 6.3.3 验证检查清单 在运行 openspec validate 之前,请确认: proposal.md 包含 ## Why 章节 proposal.md 包含 ## What Changes 章节 specs/ 下有能力文件夹(不是直接的 spec.md) 每个 spec.md 包含 Delta Header(## ADDED/MODIFIED/REMOVED Requirements) 每个需求使用 ### Requirement: <标题> 格式 每个需求至少有一个 #### Scenario: <标题> 块 每个 Scenario 使用 Gherkin 格式(Given/When/Then) 7. 常用命令参考 7.1 初始化与创建 命令 说明 示例 openspec init 初始化 OpenSpec 项目 openspec init --tools qoder openspec new change <name> 仅创建变更目录结构 openspec new change add-user-auth openspec update 更新 AI 技能和命令文件 openspec update 7.2 查看与验证 命令 说明 示例 openspec view 打开终端交互界面 openspec view openspec status --change <name> 查看变更状态 openspec status --change user-auth openspec validate <name> 验证变更文档格式 openspec validate user-auth openspec list --changes 列出所有变更 openspec list --changes openspec list --specs 列出所有规范 openspec list --specs openspec show <name> 显示变更详情 openspec show user-auth --json --deltas-only 7.3 归档与管理 命令 说明 示例 openspec archive <name> 归档已完成的变更(将 Delta 合并至 specs/ 主目录并清理 changes/ 临时目录) openspec archive user-auth 7.4 配置与调试 命令 说明 示例 openspec config list 查看当前配置 openspec config list openspec config profile 设置工作流 Profile openspec config profile openspec templates 查看内置文档模板的绝对路径 openspec templates openspec schemas 列出可用 Schema openspec schemas openspec --version 查看版本号 openspec --version openspec --help 查看帮助信息 openspec --help 7.5 全局选项 openspec <command> 选项: -V, --version 显示版本号 -h, --help 显示帮助信息 --no-color 禁用彩色输出 注意:--json 是各命令的独立选项,不是全局选项。例如 openspec show <name> --json 或 openspec validate --json。 7.6 命令速查 常用命令快速参考: # 初始化项目 openspec init --tools none # 创建变更目录(仅创建目录,不生成文档) openspec new change <name> # 列出所有变更 / 规范 openspec list --changes openspec list --specs # 验证变更 openspec validate <name> # 查看状态 openspec status --change <name> # 归档变更 openspec archive <name> # 更新工具文件 openspec update 8. 最佳实践 8.1 提案编写最佳实践 8.1.1 推荐做法 先写 Why 再写 What:先说明为什么需要这个变更,再说明具体改什么 保持简洁:proposal.md 应该是高层次的概述,详细内容放在 specs/ 中 明确范围:清楚说明 In Scope 和 Out of Scope 提供背景:让 AI 和团队成员都能理解上下文 8.1.2 避免的做法 在 proposal.md 中写详细的 API 定义(应放在 specs/ 或 design.md) 使用模糊的描述如"优化性能"、"改进体验"(应具体说明目标和指标) 忽略 Alternatives Considered 章节(说明为什么选择当前方案很重要) 8.1.3 示例对比 ❌ 不好的 Why 章节: ## Why 我们需要添加用户认证功能。 ✅ 好的 Why 章节: ## Why ### Background 当前系统没有用户认证功能,任何人都可以访问所有数据和功能。 这导致: - 无法追踪操作日志的责任人 - 敏感数据缺乏保护 - 无法实现细粒度的权限控制 ### Problem Statement 系统需要一个安全可靠的用户认证机制,支持: - 用户名密码登录 - 第三方 OAuth 登录(GitHub、Google) - 会话管理和安全退出 ### Alternatives Considered 1. **自建认证系统**:完全控制,但开发维护成本高 2. **使用 Auth0**:功能完善,但费用较高 3. **使用 Keycloak**:开源免费,支持多种协议 ✓ 已选择此方案 8.2 规范编写最佳实践 8.2.1 推荐做法 一个能力一个文件夹:按功能领域划分能力 需求粒度适中:每个需求应该是可测试的单一功能点 场景具体化:使用具体的 Gherkin 场景描述行为 优先级标注:为每个需求标注 P0/P1/P2 优先级 添加 Rationale:说明为什么需要这个需求 8.2.2 避免的做法 在一个 spec.md 中放多个不相关的能力 需求过于宽泛(如"系统应该快") 场景太模糊(如"系统应该工作") 8.3 场景编写最佳实践 8.3.1 Gherkin 格式要点 关键字 用途 示例 Given 前置条件,描述系统初始状态 Given 用户已登录系统 When 触发动作 When 用户点击"提交订单"按钮 Then 预期结果 Then 订单状态变为"待支付" And 连接多个条件或结果 And 用户收到订单确认邮件 8.3.2 好的场景示例 Scenario: 使用信用卡支付订单 Given 用户已登录系统 And 购物车中有 2 件商品,总价 299 元 And 用户已绑定信用卡 When 用户选择"信用卡支付"并确认 Then 订单创建成功 And 从信用卡扣除 299 元 And 用户收到支付成功通知 And 库存减少 2 件 8.3.3 不好的场景示例 Scenario: 支付 Given 系统 When 支付 Then 成功 问题: 太模糊,无法验证 缺少具体的前置条件 没有明确的预期结果 8.4 迭代开发最佳实践 增量添加:可以随时添加新的需求到变更中 频繁验证:使用 openspec validate 确保格式正确 版本控制:将 OpenSpec 文档纳入 Git 管理 及时归档:完成开发后使用 openspec archive 归档变更 存量项目(Brownfield)优先从小处入手:对于已有历史代码的项目,建议从一个小的、相对独立的功能开始创建第一个 Change,逐步建立规范体系,不要试图一次性为所有旧代码补规范 8.5 与 AI 协作最佳实践 8.5.1 OPSX 斜杠命令(Slash Commands,推荐) OpenSpec 1.0+ 引入了全新的 OPSX 工作流,替换了旧版的阶段锁定模式。所有命令均通过 openspec init 安装到 AI 工具对应目录。 默认 Core 配置(常用 4 个命令): 命令 作用 /opsx:propose <description> 一步创建变更并智能生成所有规划文档(AI 基于描述自动推断 kebab-case 目录名并填充 proposal/design/specs/tasks) /opsx:explore 进入探索模式,思考问题、调查代码库,不写代码 /opsx:apply 按照 tasks.md 实现任务 /opsx:archive 完成并归档当前变更 扩展工作流命令(通过 openspec config profile 开启) 命令 作用 /opsx:new 仅初始化变更目录结构,不创建文档 /opsx:continue 按依赖顺序创建下一个文档(逐步模式) /opsx:ff 快进生成所有规划文档(一步到位) /opsx:verify 验证实现是否与规范一致 /opsx:sync 将 Delta Spec 合并到主规范(不归档) /opsx:bulk-archive 批量归档多个已完成的变更 /opsx:onboard 带教 15 分钟全流程引导,适合新手上手 迁移说明:旧版命令(/openspec:proposal、/openspec:apply、/openspec:archive)已在 v1.0.0 移除。修复映射关系: /openspec:proposal → /opsx:propose /openspec:apply → /opsx:apply /openspec:archive → /opsx:archive 8.5.2 与 AI 协作的技巧 先探索后提案:不确定时先用 /opsx:explore 思考,明确后再 /opsx:propose 支持流动迭代:实现过程发现设计错误?直接编辑对应文档即可,无阶段锁定 定期清理对话上下文:开始实现任务前,建议清空当前对话上下文,确保高质量的指令注入效果 增量迭代:完成一个需求后验证,再进行下一个 8.6 团队协作最佳实践 8.6.1 代码审查清单 在 PR 审查时,检查 OpenSpec 文档: proposal.md 有清晰的 Why 和 What 每个 Requirement 都有至少一个 Scenario Scenario 使用标准的 Gherkin 格式 优先级标注合理 没有遗漏重要的边界场景 8.6.2 文档维护 保持更新:实现过程中如果发现规范需要调整,及时更新文档 同步修改:如果需求变更,先更新 spec.md 再修改代码 归档记录:归档的变更应保留历史记录,便于追溯 9. 附录 9.1 支持的 AI 工具 OpenSpec 支持 20+ AI 编程助手,以下是常用工具: 工具 类型 支持程度 Claude Code CLI + IDE 完全支持 Qoder IDE 完全支持 Cursor IDE 完全支持 JetBrains Junie IDE 插件 完全支持 Lingma IDE IDE 插件 完全支持 ForgeCode IDE 插件 完全支持 IBM Bob IDE 插件 完全支持 GitHub Copilot IDE 插件 完全支持 Cline VS Code 插件 完全支持 Windsurf IDE 完全支持 Amazon Q Developer IDE 插件 完全支持 Gemini CLI CLI 完全支持 Continue IDE 插件 完全支持 Aider CLI 支持(命令行工具,不支持 openspec init 自动生成指令) Roo Code VS Code 插件 完全支持 9.2 遥测设置 OpenSpec 收集匿名使用统计数据,用于改进产品。如需禁用: # 方法一:设置环境变量 export OPENSPEC_TELEMETRY=0 # 方法二:使用通用遥测禁用标志 export DO_NOT_TRACK=1 # 方法三:在 shell 配置文件中永久设置 echo 'export OPENSPEC_TELEMETRY=0' >> ~/.zshrc # Zsh echo 'export OPENSPEC_TELEMETRY=0' >> ~/.bashrc # Bash 9.3 常见问题 (FAQ) 9.3.1 Q1:OpenSpec 与 Swagger/OpenAPI 有什么区别? 特性 OpenSpec OpenAPI/Swagger 主要用途 需求规范驱动开发 API 接口文档 文档类型 Markdown YAML/JSON 验证方式 CLI 验证 + AI 理解 语法验证 适用阶段 开发前期(需求定义) 开发中期(接口定义) 目标用户 产品经理 + 开发者 + AI 开发者 + 前端 两者可以配合使用:先用 OpenSpec 定义需求和场景,再用 OpenAPI 定义接口细节。 9.3.2 Q2:已有的项目如何引入 OpenSpec? 在项目根目录运行 openspec init --tools none 为下一个功能创建变更提案 逐步建立规范体系,不需要一次性覆盖所有功能 9.3.3 Q3:规范写完后,AI 不遵循怎么办? 运行 openspec update 刷新 Skills 和命令文件 重启 IDE 使斜杠命令生效 在 openspec/config.yaml 的 rules: 字段添加具体约束条件 使用 /opsx:apply 让 AI 从任务清单开始实现,而不是直接要求写代码 9.3.4 Q4:多个变更可以同时进行吗? 可以。每个变更都是独立的文件夹,可以并行开发。但建议: 变更之间避免依赖关系 完成一个变更后再创建下一个 9.4 参考链接 资源 链接 官方仓库 https://github.com/Fission-AI/OpenSpec 快速入门 https://openspec.pro/getting-started/ 官方文档 https://github.com/Fission-AI/OpenSpec/tree/main/docs npm 包 https://www.npmjs.com/package/@fission-ai/openspec 配套幻灯片(旧版) openspec-user-manual-v1.pptx 配套幻灯片(当前版) openspec-user-manual-v2.pptx 文档版本: 2.1 最后更新: 2026-04-13 基于 OpenSpec v1.3.0 更新(支持新 IDE、Shell completions 优化等) -
 SDD 规范驱动开发 + Spec Kit 实战全解 SDD 规范驱动开发 + Spec Kit 实战全解 一、为什么需要 SDD AI 编程目前的主流方式是 Vibe Coding(氛围编程)——给 AI 一段提示词,AI 直接生成代码。这种方式看起来快,但实际上存在根本性问题: 问题 表现 起点模糊 需求藏在脑子里,AI 拿到的是"大概意思"而非精确描述 过程黑箱 AI 一次性生成,无法干预中间方向 结果不可预测 返工频繁,代码与预期常常偏离 迭代成本高 需求变了基本靠重写 不可追溯 为什么这么写?不知道 SDD 的诞生,就是为了解决这些问题。 二、SDD 是什么 SDD(Spec-Driven Development,规范驱动开发)——先定义清楚要做什么(What)、为什么做(Why),再让 AI 基于结构化规范去生成代码,而不是直接丢一段提示词给 AI。 2.1 与其他开发范式的关系 范式 全称 核心关注 回答的问题 DDD 领域驱动开发 业务建模与系统边界 业务是什么? BDD 行为驱动开发 业务验收与共同理解 如何验证? TDD 测试驱动开发 代码正确性 如何保证质量? SDD 规范驱动开发 人定义意图,AI 执行 如何控制 AI? 这四种范式是层级递进关系,不是替代关系。SDD 站在最顶端,负责把 DDD 的业务模型、BDD 的行为验收整理成 AI 可以精确执行的结构化规范。 2.2 SDD 的哲学 意图是唯一的真理。 规范不是代码的附属品,而是驱动一切实现的源头。 过去 现在(SDD) 文档 = 代码的附属品 代码 = 规范的产物 技术文档 = 参考 规范文档 = 产出代码的精准定义 代码是核心 规范是核心 三、SDD 的 8 步核心流程 ① Constitution ② Specify ③ Clarify(可选) 定团队原则 编写功能规范 澄清模糊需求 ④ Plan ⑤ Checklist(可选) ⑥ Tasks 制定技术计划 生成验收清单 分解任务列表 ⑦ Analyze(可选) ⑧ Implement 一致性分析 执行实现 人类负责:掌舵(定义 What & Why) AI 负责:划桨(基于规范执行 How) 第一步:Constitution — 团队宪法 做什么:建立项目核心价值观、不可违反的原则、标准、质量门槛。 原则核心:只写可执行的约束,不写模糊的理想。 ❌ 模糊理想 → ✅ 可执行约束 模糊理想 可执行约束 写高质量代码 所有函数必须有 JSDoc 注释;所有 API 必须有输入校验 schema 注重性能 列表组件数据超过 100 条时,必须使用虚拟滚动 保证安全 所有 SQL 查询必须使用参数化查询,禁止字符串拼接 代码要可维护 每个函数不超过 50 行,禁止嵌套超过 3 层 产物:.specify/memory/constitution.md 审核重点:原则是否可验证、可执行;AI 后续行为是否足够可控。 第二步:Specify — 编写功能规范 做什么:定义 What(做什么)和 Why(为什么做),专注需求本身,完全不解耦技术实现。 产物:specs/001-功能名/spec.md 规范文档标准结构: 项目概述 用户故事 功能需求 非功能需求(性能、安全、可扩展性) 验收标准(每个标准必须可验证) 约束条件 审核重点(第二个检查点): 功能是否完整无遗漏? 优先级是否清晰(MVP vs 后期迭代)? 边界条件和异常情况是否被考虑? 验收标准是否足够清晰可验证? 第三步:Clarify — 澄清需求(可选但强烈推荐) 做什么:让 AI 审视 spec.md 中模糊或未定义的地方,以 Q&A 形式向用户确认。 价值: 在写代码之前就把模糊需求全部确定 强迫开发者在动手前深度思考需求 大幅减少实现阶段的返工 典型 Q&A 场景: "这个功能的并发用户量级是多少?100 还是 10,000?" "如果 AI 生成的内容为空,系统的降级策略是什么?" "移动端的交互和 PC 端是否完全一致?" 第四步:Plan — 制定技术计划 做什么:定义 How(怎么做),提供高层技术方向,不提供具体实现细节。 关键:Plan 阶段才涉及技术选型,Specify 阶段完全不要考虑技术问题。 产物:specs/001-功能名/plan.md 包含:架构总览、目录结构、数据模型、API 契约、模块划分等 审核重点(技术决策关键节点): 目录结构是否合理、符合团队习惯? 数据库表设计是否合理、外键关系是否正确? API 端点是否完整、风格是否一致? 组件拆分粒度是否合适? 技术方案是否有不必要的复杂度? 第五步:Tasks — 分解任务 做什么:将技术计划转换为 AI 可逐个执行的原子化工作项。 产物:specs/001-功能名/tasks.md 结构: Phase 1 T001 - 可并行任务 T002 - 可并行任务 T003 - 依赖 T001 完成 Phase 2 ... 标记 的任务 = 可并行执行,这是 Spec Kit 提升开发速度的核心机制。 审核重点: 依赖关系是否合理,有无循环依赖? 任务粒度是否足够小,能否在单次 AI 交互中完成? 需求映射是否完整,每个任务能否追溯到具体需求? Phase 划分是否合理? 第六步:Analyze — 一致性分析(可选但推荐) 做什么:对比 spec.md、plan.md、tasks.md 三者之间的一致性,找出潜在遗漏或矛盾点。 产物:一致性分析报告 检查项 说明 覆盖率 每个需求是否都有对应任务? 一致性 spec 和 plan 之间是否有矛盾? 完整性 tasks 是否完整覆盖 plan? 边界条件 异常流程是否被覆盖? 价值:在动手写代码之前发现文档间的不一致,避免实现阶段大规模返工。 第七步:Implement — 执行实现 做什么:按任务列表顺序执行,生成代码、测试、文档。 AI 在 Implement 阶段会执行 5 件事: 读取所有文档(spec、plan、tasks) 按顺序和依赖关系逐个执行任务 为每个任务生成代码、测试、文档 在 tasks.md 中标记已完成的任务 确保合规 关键节点检查(人类必须介入的三个时机): 时机 检查内容 Phase 完成后 运行项目,确保基本功能正常 任意时刻 运行单元测试,确保覆盖率达标 全程 审查关键代码文件,确认风格和架构符合预期 如果 AI 生成的代码有问题——不要直接改代码,而是回到 spec.md 或 plan.md 修正规范,再重新 Implement。这是 SDD 的核心优势:系统性修正,而非打补丁。 四、Spec Kit 安装与使用 环境准备 # 1. 安装 UV(包管理器) powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex" # 验证安装 uv --version # 2. 用 UV 安装 Spec Kit uv tool install specify-cli --from git+https://github.com/github/spec-kit.git # 验证安装 specify --help specify check 初始化项目 # 创建独立项目 specify init my-feature --ai claude --script ps # 在当前目录初始化(不创建子目录) specify init --here --force --ai claude --script ps ⚠️ 前提:项目必须已初始化 Git 仓库(git init) 项目初始化后自动生成的目录结构 项目名/ ├── .claude/commands/ # Claude Code 斜杠命令(/speckit.*) ├── .specify/ │ ├── memory/ │ │ └── constitution.md # 团队宪法 │ ├── scripts/ # 辅助脚本 │ └── templates/ # 文档模板 └── specs/ # 功能规范(按编号管理) └── 001-功能名/ ├── spec.md # 功能规范 ├── plan.md # 技术计划 ├── tasks.md # 任务列表 ├── data-model.md # 数据模型 ├── quickstart.md # 快速启动 └── research.md # 研究文档 五、Spec Kit 适用场景判断 场景 推荐方式 快速原型 / 小脚本 / 一次性需求 Vibe Coding(普通 AI Coding) 中大型项目 / 团队协作 / 长期维护 SDD + Spec Kit Bug 修复 Cursor(项目索引 RAG 定位更精准) 一个简单的判断标准:如果项目复杂到在写代码之前就需要考虑架构和数据模型,就值得用 SDD。 六、进阶技巧与最佳实践 1. 规范力度控制(大型项目) 按功能拆分规范,而非把所有功能写在一个巨大的 spec.md 里。 specs/ ├── 001-auth/ # 认证功能,独立走完完整流程 ├── 002-blog-post/ # 博客文章功能 ├── 003-comment/ # 评论功能 └── 004-search/ # 搜索功能 好处: AI 上下文窗口不会被撑爆 每个功能可独立验收 出问题更容易定位根因 2. 迭代开发模式 添加新功能 ≠ 修改旧规范,而是回到 /speckit.specify,Spec Kit 会自动创建新的编号目录(003-新功能),不影响已有功能规范。 3. 用 Checklist 做规范级"单元测试" /speckit.checklist 生成验收清单,相当于给规范做一次完整性检查,确保每个需求都有对应实现。 4. 修改顺序:规范 → 代码 AI 生成的代码不符合预期时: ❌ 直接改代码(打补丁,下次可能又被覆盖) ✅ 回到 spec.md / plan.md 修正规范,重新 Implement(系统性修正) 5. .specify 目录必须提交 Git .specify/ 是项目的重要资产,包含团队的规范和决策上下文,必须版本控制,确保: 团队所有人访问一致的上下文 新加入的 AI 也能获得完整背景 七、常见问题解答 Q1:Spec Kit 只能和 Claude Code 一起用? 不是。Spec Kit 支持 Copilot、Claude Code、Gemini CLI、Cursor 等多种 AI 编程工具。同样,Claude Code 也不只能用 Spec Kit,也可以配合 OpenSpec 等其他 SDD 工具。 Q2:小型项目用 SDD 是否过于复杂? 是。SDD 更适合中大型项目。如果复杂到需要先考虑架构和数据模型,就值得用 SDD。简单到几个小时能做完的小脚本,直接 Vibe Coding 更高效。 Q3:规范文件是否需要手动维护? 可以直接编辑 markdown 文件,但更推荐通过 Claude Code 修改——AI 会确保修改后的文档和其他文件保持一致,避免手动编辑引入的不一致。 Q4:一次 Implement 没跑完所有任务怎么办? 完全正常。可用 /speckit.implement 继续,或者用提示词指定实现某个 Phase 的任务: 继续完成 Phase 2 的剩余任务 Q5:如何更新模板? specify init --here --force 加上 --force 会更新模板和命令文件,但不会覆盖已有的 specs/ 目录和源代码。 八、核心总结 SDD 的本质 把软件开发从"直接写代码"转换为"先定义意图,再生成代码"。规范是源头,代码是产物。 人类 vs AI 的分工 角色 职责 人类(掌舵者) 定义意图、审核产出、做最终决策 AI(执行者) 在每个阶段忠实地执行人类意图 完整实践路径 安装环境 ↓ 初始化项目(specify init) ↓ 定义原则(/speckit.constitution) ← 第一个检查点 ↓ 编写规范(/speckit.specify) ← 第二个检查点 ↓ 澄清规范(/speckit.clarify) ← 可选,推荐做 ↓ 制定计划(/speckit.plan) ← 第三个检查点 ↓ 生成任务(/speckit.tasks) ← 第四个检查点 ↓ 一致性分析(/speckit.analyze) ← 可选,推荐做 ↓ 执行实现(/speckit.implement) ← 最终验收 SDD 的核心价值 维度 提升 可控性 每个阶段都有检查点,方向始终可干预 可追溯性 每步都有文档记录,决策有据可查 迭代成本 修改规范即可重新生成代码,无需重写 团队协作 规范作为共同语言,减少沟通偏差 AI 使用质量 从"开盲盒"变为"按图施工" 视频标题:告别盲盒式编程!用 SDD + Spec Kit 让 AI 按图施工|AI 编程实战 #03 作者:NOVA 平台:Bilibili 原链接:https://www.bilibili.com/video/BV1QvwuzTEoT 字幕字符数:8,318 字 内容深度:★★★★★ 整理依据:Bilibili 视频字幕原文(8,318 字),视频作者 NOVA,AI 编程实战系列第 3 期
SDD 规范驱动开发 + Spec Kit 实战全解 SDD 规范驱动开发 + Spec Kit 实战全解 一、为什么需要 SDD AI 编程目前的主流方式是 Vibe Coding(氛围编程)——给 AI 一段提示词,AI 直接生成代码。这种方式看起来快,但实际上存在根本性问题: 问题 表现 起点模糊 需求藏在脑子里,AI 拿到的是"大概意思"而非精确描述 过程黑箱 AI 一次性生成,无法干预中间方向 结果不可预测 返工频繁,代码与预期常常偏离 迭代成本高 需求变了基本靠重写 不可追溯 为什么这么写?不知道 SDD 的诞生,就是为了解决这些问题。 二、SDD 是什么 SDD(Spec-Driven Development,规范驱动开发)——先定义清楚要做什么(What)、为什么做(Why),再让 AI 基于结构化规范去生成代码,而不是直接丢一段提示词给 AI。 2.1 与其他开发范式的关系 范式 全称 核心关注 回答的问题 DDD 领域驱动开发 业务建模与系统边界 业务是什么? BDD 行为驱动开发 业务验收与共同理解 如何验证? TDD 测试驱动开发 代码正确性 如何保证质量? SDD 规范驱动开发 人定义意图,AI 执行 如何控制 AI? 这四种范式是层级递进关系,不是替代关系。SDD 站在最顶端,负责把 DDD 的业务模型、BDD 的行为验收整理成 AI 可以精确执行的结构化规范。 2.2 SDD 的哲学 意图是唯一的真理。 规范不是代码的附属品,而是驱动一切实现的源头。 过去 现在(SDD) 文档 = 代码的附属品 代码 = 规范的产物 技术文档 = 参考 规范文档 = 产出代码的精准定义 代码是核心 规范是核心 三、SDD 的 8 步核心流程 ① Constitution ② Specify ③ Clarify(可选) 定团队原则 编写功能规范 澄清模糊需求 ④ Plan ⑤ Checklist(可选) ⑥ Tasks 制定技术计划 生成验收清单 分解任务列表 ⑦ Analyze(可选) ⑧ Implement 一致性分析 执行实现 人类负责:掌舵(定义 What & Why) AI 负责:划桨(基于规范执行 How) 第一步:Constitution — 团队宪法 做什么:建立项目核心价值观、不可违反的原则、标准、质量门槛。 原则核心:只写可执行的约束,不写模糊的理想。 ❌ 模糊理想 → ✅ 可执行约束 模糊理想 可执行约束 写高质量代码 所有函数必须有 JSDoc 注释;所有 API 必须有输入校验 schema 注重性能 列表组件数据超过 100 条时,必须使用虚拟滚动 保证安全 所有 SQL 查询必须使用参数化查询,禁止字符串拼接 代码要可维护 每个函数不超过 50 行,禁止嵌套超过 3 层 产物:.specify/memory/constitution.md 审核重点:原则是否可验证、可执行;AI 后续行为是否足够可控。 第二步:Specify — 编写功能规范 做什么:定义 What(做什么)和 Why(为什么做),专注需求本身,完全不解耦技术实现。 产物:specs/001-功能名/spec.md 规范文档标准结构: 项目概述 用户故事 功能需求 非功能需求(性能、安全、可扩展性) 验收标准(每个标准必须可验证) 约束条件 审核重点(第二个检查点): 功能是否完整无遗漏? 优先级是否清晰(MVP vs 后期迭代)? 边界条件和异常情况是否被考虑? 验收标准是否足够清晰可验证? 第三步:Clarify — 澄清需求(可选但强烈推荐) 做什么:让 AI 审视 spec.md 中模糊或未定义的地方,以 Q&A 形式向用户确认。 价值: 在写代码之前就把模糊需求全部确定 强迫开发者在动手前深度思考需求 大幅减少实现阶段的返工 典型 Q&A 场景: "这个功能的并发用户量级是多少?100 还是 10,000?" "如果 AI 生成的内容为空,系统的降级策略是什么?" "移动端的交互和 PC 端是否完全一致?" 第四步:Plan — 制定技术计划 做什么:定义 How(怎么做),提供高层技术方向,不提供具体实现细节。 关键:Plan 阶段才涉及技术选型,Specify 阶段完全不要考虑技术问题。 产物:specs/001-功能名/plan.md 包含:架构总览、目录结构、数据模型、API 契约、模块划分等 审核重点(技术决策关键节点): 目录结构是否合理、符合团队习惯? 数据库表设计是否合理、外键关系是否正确? API 端点是否完整、风格是否一致? 组件拆分粒度是否合适? 技术方案是否有不必要的复杂度? 第五步:Tasks — 分解任务 做什么:将技术计划转换为 AI 可逐个执行的原子化工作项。 产物:specs/001-功能名/tasks.md 结构: Phase 1 T001 - 可并行任务 T002 - 可并行任务 T003 - 依赖 T001 完成 Phase 2 ... 标记 的任务 = 可并行执行,这是 Spec Kit 提升开发速度的核心机制。 审核重点: 依赖关系是否合理,有无循环依赖? 任务粒度是否足够小,能否在单次 AI 交互中完成? 需求映射是否完整,每个任务能否追溯到具体需求? Phase 划分是否合理? 第六步:Analyze — 一致性分析(可选但推荐) 做什么:对比 spec.md、plan.md、tasks.md 三者之间的一致性,找出潜在遗漏或矛盾点。 产物:一致性分析报告 检查项 说明 覆盖率 每个需求是否都有对应任务? 一致性 spec 和 plan 之间是否有矛盾? 完整性 tasks 是否完整覆盖 plan? 边界条件 异常流程是否被覆盖? 价值:在动手写代码之前发现文档间的不一致,避免实现阶段大规模返工。 第七步:Implement — 执行实现 做什么:按任务列表顺序执行,生成代码、测试、文档。 AI 在 Implement 阶段会执行 5 件事: 读取所有文档(spec、plan、tasks) 按顺序和依赖关系逐个执行任务 为每个任务生成代码、测试、文档 在 tasks.md 中标记已完成的任务 确保合规 关键节点检查(人类必须介入的三个时机): 时机 检查内容 Phase 完成后 运行项目,确保基本功能正常 任意时刻 运行单元测试,确保覆盖率达标 全程 审查关键代码文件,确认风格和架构符合预期 如果 AI 生成的代码有问题——不要直接改代码,而是回到 spec.md 或 plan.md 修正规范,再重新 Implement。这是 SDD 的核心优势:系统性修正,而非打补丁。 四、Spec Kit 安装与使用 环境准备 # 1. 安装 UV(包管理器) powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex" # 验证安装 uv --version # 2. 用 UV 安装 Spec Kit uv tool install specify-cli --from git+https://github.com/github/spec-kit.git # 验证安装 specify --help specify check 初始化项目 # 创建独立项目 specify init my-feature --ai claude --script ps # 在当前目录初始化(不创建子目录) specify init --here --force --ai claude --script ps ⚠️ 前提:项目必须已初始化 Git 仓库(git init) 项目初始化后自动生成的目录结构 项目名/ ├── .claude/commands/ # Claude Code 斜杠命令(/speckit.*) ├── .specify/ │ ├── memory/ │ │ └── constitution.md # 团队宪法 │ ├── scripts/ # 辅助脚本 │ └── templates/ # 文档模板 └── specs/ # 功能规范(按编号管理) └── 001-功能名/ ├── spec.md # 功能规范 ├── plan.md # 技术计划 ├── tasks.md # 任务列表 ├── data-model.md # 数据模型 ├── quickstart.md # 快速启动 └── research.md # 研究文档 五、Spec Kit 适用场景判断 场景 推荐方式 快速原型 / 小脚本 / 一次性需求 Vibe Coding(普通 AI Coding) 中大型项目 / 团队协作 / 长期维护 SDD + Spec Kit Bug 修复 Cursor(项目索引 RAG 定位更精准) 一个简单的判断标准:如果项目复杂到在写代码之前就需要考虑架构和数据模型,就值得用 SDD。 六、进阶技巧与最佳实践 1. 规范力度控制(大型项目) 按功能拆分规范,而非把所有功能写在一个巨大的 spec.md 里。 specs/ ├── 001-auth/ # 认证功能,独立走完完整流程 ├── 002-blog-post/ # 博客文章功能 ├── 003-comment/ # 评论功能 └── 004-search/ # 搜索功能 好处: AI 上下文窗口不会被撑爆 每个功能可独立验收 出问题更容易定位根因 2. 迭代开发模式 添加新功能 ≠ 修改旧规范,而是回到 /speckit.specify,Spec Kit 会自动创建新的编号目录(003-新功能),不影响已有功能规范。 3. 用 Checklist 做规范级"单元测试" /speckit.checklist 生成验收清单,相当于给规范做一次完整性检查,确保每个需求都有对应实现。 4. 修改顺序:规范 → 代码 AI 生成的代码不符合预期时: ❌ 直接改代码(打补丁,下次可能又被覆盖) ✅ 回到 spec.md / plan.md 修正规范,重新 Implement(系统性修正) 5. .specify 目录必须提交 Git .specify/ 是项目的重要资产,包含团队的规范和决策上下文,必须版本控制,确保: 团队所有人访问一致的上下文 新加入的 AI 也能获得完整背景 七、常见问题解答 Q1:Spec Kit 只能和 Claude Code 一起用? 不是。Spec Kit 支持 Copilot、Claude Code、Gemini CLI、Cursor 等多种 AI 编程工具。同样,Claude Code 也不只能用 Spec Kit,也可以配合 OpenSpec 等其他 SDD 工具。 Q2:小型项目用 SDD 是否过于复杂? 是。SDD 更适合中大型项目。如果复杂到需要先考虑架构和数据模型,就值得用 SDD。简单到几个小时能做完的小脚本,直接 Vibe Coding 更高效。 Q3:规范文件是否需要手动维护? 可以直接编辑 markdown 文件,但更推荐通过 Claude Code 修改——AI 会确保修改后的文档和其他文件保持一致,避免手动编辑引入的不一致。 Q4:一次 Implement 没跑完所有任务怎么办? 完全正常。可用 /speckit.implement 继续,或者用提示词指定实现某个 Phase 的任务: 继续完成 Phase 2 的剩余任务 Q5:如何更新模板? specify init --here --force 加上 --force 会更新模板和命令文件,但不会覆盖已有的 specs/ 目录和源代码。 八、核心总结 SDD 的本质 把软件开发从"直接写代码"转换为"先定义意图,再生成代码"。规范是源头,代码是产物。 人类 vs AI 的分工 角色 职责 人类(掌舵者) 定义意图、审核产出、做最终决策 AI(执行者) 在每个阶段忠实地执行人类意图 完整实践路径 安装环境 ↓ 初始化项目(specify init) ↓ 定义原则(/speckit.constitution) ← 第一个检查点 ↓ 编写规范(/speckit.specify) ← 第二个检查点 ↓ 澄清规范(/speckit.clarify) ← 可选,推荐做 ↓ 制定计划(/speckit.plan) ← 第三个检查点 ↓ 生成任务(/speckit.tasks) ← 第四个检查点 ↓ 一致性分析(/speckit.analyze) ← 可选,推荐做 ↓ 执行实现(/speckit.implement) ← 最终验收 SDD 的核心价值 维度 提升 可控性 每个阶段都有检查点,方向始终可干预 可追溯性 每步都有文档记录,决策有据可查 迭代成本 修改规范即可重新生成代码,无需重写 团队协作 规范作为共同语言,减少沟通偏差 AI 使用质量 从"开盲盒"变为"按图施工" 视频标题:告别盲盒式编程!用 SDD + Spec Kit 让 AI 按图施工|AI 编程实战 #03 作者:NOVA 平台:Bilibili 原链接:https://www.bilibili.com/video/BV1QvwuzTEoT 字幕字符数:8,318 字 内容深度:★★★★★ 整理依据:Bilibili 视频字幕原文(8,318 字),视频作者 NOVA,AI 编程实战系列第 3 期 -
在 Claude Code 里安装并使用 Spec-Kit 在 Claude Code 里安装并使用 Spec-Kit Spec-Kit 是什么 Spec-Kit 是微软发布的"规格驱动开发(SDD)"工具包,适配 Claude Code、Copilot、Gemini CLI 等 AI Coding 代理。 核心作用是:把"规格→计划→任务→实现"的流程标准化,做成可执行的斜杠命令,让 AI Coding 有章可循,而不是凭感觉写代码。 核心用途集中在三方面: 项目初始化:快速生成带规范目录(.specify/、specs/、scripts/)和模板的项目骨架 流程标准化:提供 /speckit.constitution、/speckit.specify、/speckit.plan 等斜杠命令,覆盖从需求澄清到任务拆解的全流程 一致性保障:通过 /speckit.analyze 检查需求文档、技术方案、任务列表之间的矛盾或遗漏 Spec-Kit 能解决什么问题 让"写什么/为什么"(Spec)先于"怎么做"(Plan/Tasks/Impl),减少返工;给代理提供统一的"宪法"和护栏;产出一套可追溯的工件与目录结构。 一个更直白的理解 他是增加 tokens 消耗,减少人脑消耗的一种方式,而且这是大模型时代的正确思考方式。 spec-kit 会大幅增加开发时间,大幅增加 tokens 消耗,但这个过程中你可以看着就好,去干点其他事情。相当于你招了一个成熟下属,虽然你的命令表达不特别清晰,但是他会中规中矩按照自己理解给你全部做的好好的。虽然结果可能和你最开始的想法不完全一致,但你心里的台词是,"也还行,就这样吧"。 完整安装步骤(Windows + PowerShell) 一、安装 uv powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex" 重开一个新的 PowerShell 后运行: uv --version 如果提示找不到命令,执行: uv tool update-shell (或者把 C:\Users\<你>\.local\bin 加到 PATH) 二、用 uv 安装 Specify CLI uv tool install specify-cli --from git+https://github.com/github/spec-kit.git specify --help specify check 三、确认 Claude Code 可用 claude --version 四、初始化项目骨架 在打算放项目的目录里运行: specify init my-feature --ai claude --script ps 如果你是新开发,直接在根目录下,用: specify init --here --force --ai claude --script ps ⚠️ 注意:spec-kit 基于 git 管理项目,在运行以上命令之前,需要先 git push。 初始化后会生成 .specify/、templates/、specs/、scripts/ 等目录与模板,且模板会自动注入 /speckit.* 斜杠命令供代理使用。 五、跑完整的 Spec-Driven 工作流 cd my-feature claude 在 Claude Code 里依次发送以下命令: 步骤 命令 说明 1 /speckit.constitution 建立项目原则,生成 .specify/memory/constitution.md 2 /speckit.specify 撰写功能规格,专注"做什么 & 为什么",不要先纠结技术栈 3 /speckit.clarify 结构化澄清需求,通过 Q&A 消除模糊点(可选) 4 /speckit.plan 产出技术实现方案(这一步再指定技术栈、架构) 5 /speckit.tasks 从实现方案拆解成可执行的任务列表 6 /speckit.analyze 检查所有工件的一致性与覆盖率 7 /speckit.implement 一键执行实现(按依赖顺序执行任务) 💡 标记 的 task 是可以并行执行的,Claude Code 会自动分配多个 task agent 并行处理。 怎么自动完成整个流程 spec-kit 的初衷是让用户每步确认产出并修正,但如果你想像作者一样一句话让 Claude Code 自动跑完全流程,可以建一个 subagent: --- name: spec-kit-feature-agent description: Use this agent when the user explicitly mentions using 'spec-kit'... model: inherit --- You are a Spec-Kit Feature Implementation Agent... Your core workflow follows this exact order: 1. /speckit.constitution 2. /speckit.specify 3. /speckit.clarify 4. /speckit.checklist 5. /speckit.plan 6. /speckit.tasks 7. /speckit.analyze 8. /speckit.checklist 9. /speckit.implement 作者实测:一句话命令后,agent 一次执行了 13M tokens,自动依次执行了 /speckit.constitution → /speckit.specify → /speckit.plan → /speckit.tasks → /speckit.implement,并按依赖顺序并行执行了多个任务。 💡 在 subagent 中可以自动发出 /command,而在 Claude Code 的 /command 里要求自动执行其他 /command 是不生效的。 spec-kit 的适用场景 适合的场景: 从 0 到 1 搭建新需求 需要稳定、完整地搭建一个功能模块 不适用的场景: Bug Fix:Claude Code 没有项目索引,项目大了之后 Grep 查回来的片段既不精准也耗 tokens/time,不如 Cursor 的 RAG 精准定位问题 常见问题 安装时报错 typer 找不到? pip install typer 如果仍然报错,可能是 specify-cli 版本问题,可尝试指定版本安装或查看官方最新解决方案。 spec-kit 太复杂怎么办? 可以看轻量版 OpenSpec,更适合 MVP 阶段。0-1 用 spec-kit,1-n 用 OpenSpec 更合适。 总结 特点 说明 核心理念 规格驱动开发(Spec-Driven Development) 适用阶段 0-1 新功能搭建 tokens 消耗 大(但省人脑) 开发时间 长(但省人工干预) 最佳搭档 Claude Code(支持并行 task) 轻量替代 OpenSpec
-
 让 Claude Code 一直干下去 让 Claude Code 一直干下去 三种方案,按安全性从高到低排列 方案一:Auto Mode(推荐) Auto Mode 是介于"每次手动审批"和"完全跳过权限"之间的中间路线。在每个工具调用执行前,分类器会自动审查是否安全,安全的操作自动放行,危险的操作被拦截。 # 启动时开启 claude --enable-auto-mode # 启动后用 Shift+Tab 循环切换模式 # 默认模式 → 自动接受编辑 → Auto Mode → 计划模式 # 非交互模式 claude -p "重构认证模块" --permission-mode auto 安全机制: 如果一个会话中连续触发 3 次拦截,或累计触发 20 次,系统会暂停并重新要求人工确认。 方案二:--dangerously-skip-permissions(YOLO 模式) 完全跳过所有权限提示,Claude 不间断工作直到任务完成。仅推荐在隔离的容器/沙箱环境中使用。 # 基础用法 claude --dangerously-skip-permissions "实现支付功能" # 配合预算限制(防止费用失控) claude --dangerously-skip-permissions --max-budget-usd 5.00 "大规模重构" # 配合命名会话(事后可恢复) claude --dangerously-skip-permissions -n "refactor-sprint" "继续重构" # 非交互流水线模式 claude -p --dangerously-skip-permissions "生成报告" ⚠️ 警告: 有真实生产凭证、SSH key、数据库连接的机器上不要用。 方案三:精细配置 allowedTools 不想完全放权,只对特定操作免审批: # 只允许特定命令免审批 claude --allowedTools "Bash(git *),Bash(npm *),Read,Write" 在 settings.json 中永久配置: // ~/.claude/settings.json { "permissions": { "allowedTools": , "deny": } } 模式对比 模式 自主程度 安全性 适合场景 默认模式 低(每步确认) 最高 敏感操作、生产环境 Auto Mode 高(分类器把关) 较高 日常长任务开发 allowedTools 中(精细控制) 高 指定范围自动化 --dangerously-skip-permissions 最高(无限制) 低 隔离容器/CI 实战组合技 # 先用 Plan Mode 规划,再切换到 Auto Mode 执行 # 1. 启动时进入计划模式(只读,不执行) claude --enable-auto-mode # Shift+Tab 切到 Plan Mode → 让 Claude 分析和规划 # 确认计划后 → Shift+Tab 切到 Auto Mode → 开始执行 # 配合预算上限 + 命名会话,安全地跑长任务 claude --dangerously-skip-permissions \ --max-budget-usd 10.00 \ -n "big-refactor" \ "按照 CLAUDE.md 的规范,完整重构 src/ 目录下所有组件" 核心建议 跑大任务前先 git commit 一次,留好退路。出了问题 git reset 救场。
让 Claude Code 一直干下去 让 Claude Code 一直干下去 三种方案,按安全性从高到低排列 方案一:Auto Mode(推荐) Auto Mode 是介于"每次手动审批"和"完全跳过权限"之间的中间路线。在每个工具调用执行前,分类器会自动审查是否安全,安全的操作自动放行,危险的操作被拦截。 # 启动时开启 claude --enable-auto-mode # 启动后用 Shift+Tab 循环切换模式 # 默认模式 → 自动接受编辑 → Auto Mode → 计划模式 # 非交互模式 claude -p "重构认证模块" --permission-mode auto 安全机制: 如果一个会话中连续触发 3 次拦截,或累计触发 20 次,系统会暂停并重新要求人工确认。 方案二:--dangerously-skip-permissions(YOLO 模式) 完全跳过所有权限提示,Claude 不间断工作直到任务完成。仅推荐在隔离的容器/沙箱环境中使用。 # 基础用法 claude --dangerously-skip-permissions "实现支付功能" # 配合预算限制(防止费用失控) claude --dangerously-skip-permissions --max-budget-usd 5.00 "大规模重构" # 配合命名会话(事后可恢复) claude --dangerously-skip-permissions -n "refactor-sprint" "继续重构" # 非交互流水线模式 claude -p --dangerously-skip-permissions "生成报告" ⚠️ 警告: 有真实生产凭证、SSH key、数据库连接的机器上不要用。 方案三:精细配置 allowedTools 不想完全放权,只对特定操作免审批: # 只允许特定命令免审批 claude --allowedTools "Bash(git *),Bash(npm *),Read,Write" 在 settings.json 中永久配置: // ~/.claude/settings.json { "permissions": { "allowedTools": , "deny": } } 模式对比 模式 自主程度 安全性 适合场景 默认模式 低(每步确认) 最高 敏感操作、生产环境 Auto Mode 高(分类器把关) 较高 日常长任务开发 allowedTools 中(精细控制) 高 指定范围自动化 --dangerously-skip-permissions 最高(无限制) 低 隔离容器/CI 实战组合技 # 先用 Plan Mode 规划,再切换到 Auto Mode 执行 # 1. 启动时进入计划模式(只读,不执行) claude --enable-auto-mode # Shift+Tab 切到 Plan Mode → 让 Claude 分析和规划 # 确认计划后 → Shift+Tab 切到 Auto Mode → 开始执行 # 配合预算上限 + 命名会话,安全地跑长任务 claude --dangerously-skip-permissions \ --max-budget-usd 10.00 \ -n "big-refactor" \ "按照 CLAUDE.md 的规范,完整重构 src/ 目录下所有组件" 核心建议 跑大任务前先 git commit 一次,留好退路。出了问题 git reset 救场。 -
Claude Code 常用命令大全 Claude Code 常用命令大全 整理版本:2026年4月 | 适用:Claude Code CLI & IDE 插件 目录 基础会话命令 文件与上下文管理 代码操作命令 Git 集成命令 项目与任务管理 MCP 服务器命令 配置与权限命令 /loop 软件开发检测命令 /loop 项目构建全套检查命令 一、基础会话命令 命令 说明 claude 启动交互式 REPL 会话 claude "你的问题" 非交互式单次查询 claude -p "提示词" 使用 -p 指定 prompt 直接运行 claude --model claude-sonnet-4-20250514 指定模型版本 claude --version 查看当前版本 claude --help 显示帮助信息 /exit 或 /quit 退出当前会话 /clear 清除当前对话上下文 /reset 重置会话状态 /help 显示可用命令列表 二、文件与上下文管理 命令 说明 @文件路径 将文件内容注入到上下文(如 @src/main.py) @目录/ 将整个目录结构注入上下文 /add 文件路径 添加文件到当前会话上下文 /context 查看当前上下文中已加载的文件列表 /context clear 清空上下文文件 /read 文件路径 读取并显示文件内容 cat 文件 \| claude -p "分析这个" 通过管道传入文件内容 claude < input.txt 从标准输入读取内容 三、代码操作命令 命令 说明 /edit 文件路径 打开文件进行编辑 /diff 查看当前会话中的代码变更 diff /apply 应用 Claude 生成的代码变更 /revert 撤销最近一次代码变更 /run 命令 在 shell 中执行命令并将结果返回给 Claude /test 运行项目测试(自动检测测试框架) /lint 运行代码静态分析 /format 格式化代码文件 /fix 让 Claude 自动修复检测到的错误 /explain 解释选中或当前文件的代码逻辑 /review 对当前代码进行 Code Review /refactor 重构指定代码段 /optimize 对代码进行性能优化建议 四、Git 集成命令 命令 说明 /git status 查看 Git 状态 /git diff 查看未提交变更 /git log 查看提交历史 /git commit -m "msg" 提交变更(Claude 可辅助生成 commit message) /git pr 创建或查看 Pull Request 描述 /commit 让 Claude 自动生成并执行 commit(含 message) /pr-description 自动生成 PR 描述文本 /changelog 基于 git log 生成变更日志 五、项目与任务管理 命令 说明 /init 初始化项目,生成 CLAUDE.md 配置文件 /project 查看当前项目信息 /todo 显示或管理待办任务列表 /todo add "任务描述" 新增一个任务 /todo done 编号 标记任务为完成 /plan "目标" 让 Claude 输出完成目标的步骤计划 /architect "描述" 生成系统架构设计方案 /docs 生成或更新项目文档 /readme 自动生成或更新 README.md 六、MCP 服务器命令 命令 说明 claude mcp list 列出所有已配置的 MCP 服务器 claude mcp add 名称 命令 添加新的 MCP 服务器 claude mcp remove 名称 移除指定 MCP 服务器 claude mcp get 名称 查看指定 MCP 服务器详情 claude mcp add-json 名称 '{"type":"stdio",...}' 以 JSON 格式添加 MCP 服务器 claude mcp add --scope user 添加用户级别的 MCP 服务器 claude mcp add --scope project 添加项目级别的 MCP 服务器 claude mcp serve 将 Claude Code 作为 MCP 服务器启动 七、配置与权限命令 命令 说明 claude config list 查看所有配置项 claude config get 键名 获取指定配置值 claude config set 键名 值 设置配置项 claude config set model claude-sonnet-4-20250514 设置默认模型 claude --allowedTools "Bash,Read,Write" 限制允许使用的工具 claude --disallowedTools "Bash" 禁用指定工具 claude --permission-mode auto 设置权限模式为自动 claude --permission-mode ask 每次操作前询问权限(默认) claude --permission-mode bypass 跳过权限询问(谨慎使用) /permissions 查看当前会话的权限设置 八、/loop 软件开发检测命令 /loop 是 Claude Code 的自主循环执行模式,适合持续检测、自动修复、CI 集成等场景。 以下为软件开发场景下的实用 /loop 检测指令集合。 🔍 代码质量检测 # 持续监控并修复 lint 错误 /loop "运行 eslint . --fix,修复所有报错,循环直到 0 错误" # 循环检测 TypeScript 类型错误 /loop "运行 tsc --noEmit,分析类型错误,逐一修复,直到编译通过" # 检测并修复 Python 代码规范 /loop "运行 flake8 . 和 black --check .,自动格式化并修复,直到无警告" # 循环检测代码复杂度 /loop "使用 radon cc . 分析圈复杂度,对复杂度超过 10 的函数进行重构简化" 🧪 测试自动化检测 # 循环运行测试直到全部通过 /loop "运行 npm test,分析失败用例,修复对应代码,直到所有测试绿灯" # 持续检测测试覆盖率 /loop "运行 pytest --cov=. --cov-report=term,分析未覆盖代码,补充单元测试,直到覆盖率 >= 80%" # 循环检测并修复集成测试 /loop "运行 npm run test:integration,失败时分析日志,逐步修复,直到全部通过" # E2E 测试监控循环 /loop "运行 playwright test,失败时截图分析,修复页面逻辑,直到所有场景通过" 🔒 安全漏洞检测 # 循环扫描依赖漏洞 /loop "运行 npm audit,分析高危漏洞,升级或替换危险依赖,直到无高危警告" # Python 依赖安全扫描 /loop "运行 safety check,修复所有已知漏洞依赖,直到扫描通过" # 代码安全静态分析 /loop "运行 bandit -r . -ll,分析安全问题,修复高风险代码,直到无 HIGH 级别警告" # Secret 泄露检测 /loop "运行 gitleaks detect,找出泄露的密钥或 token,替换为环境变量,直到检测干净" 🏗️ 构建与编译检测 # 循环修复构建错误 /loop "运行 npm run build,分析构建错误日志,逐一修复,直到构建成功" # Docker 镜像构建检测 /loop "运行 docker build .,分析 Dockerfile 错误,修复后重新构建,直到镜像生成成功" # Gradle/Maven 构建检测 /loop "运行 ./gradlew build,分析编译失败原因,修复 Java 代码,直到构建 BUILD SUCCESS" # Go 编译检测 /loop "运行 go build ./...,修复所有编译错误,直到 go vet ./... 无任何警告" 📊 性能检测 # 循环检测 API 响应时间 /loop "运行 k6 run load_test.js,分析响应时间超标的接口,优化对应逻辑,直到 P95 < 200ms" # 数据库慢查询检测 /loop "分析 slow_query.log,找出执行时间 > 1s 的 SQL,添加索引或重写查询,直到无慢查询" # Bundle 体积检测 /loop "运行 webpack-bundle-analyzer,找出超过 500KB 的模块,进行代码分割或懒加载,直到主 bundle < 1MB" # 内存泄漏检测 /loop "运行 node --inspect app.js,使用 heap snapshot 分析内存增长,修复泄漏点,直到内存稳定" 🔄 CI/CD 流水线检测 # 循环修复 CI 失败 /loop "读取 .github/workflows/*.yml 的最新 CI 失败日志,分析原因,修复代码或配置,直到流水线全绿" # 环境变量配置检测 /loop "检查 .env.example 与代码中使用的环境变量是否一致,补全缺失变量声明,直到完全同步" # 依赖版本锁定检测 /loop "对比 package.json 与 package-lock.json,找出版本不一致项,统一锁定版本,直到无冲突" # 容器健康检测 /loop "运行 docker-compose up,检查所有服务健康状态,修复启动失败的服务,直到全部 healthy" 📝 文档与注释检测 # 循环检测缺少 JSDoc 的函数 /loop "使用 eslint --rule jsdoc/require-jsdoc 扫描,为未注释的 public 函数添加 JSDoc,直到无警告" # API 文档同步检测 /loop "对比 OpenAPI spec 与实际路由定义,补全缺失的接口文档,直到两者完全一致" # README 完整性检测 /loop "检查 README.md 是否包含安装、使用、配置、贡献指南四个章节,补全缺失内容" # 代码注释覆盖率检测 /loop "统计项目中公共函数的注释覆盖率,对未注释函数逐一添加说明,直到覆盖率 >= 90%" 🗃️ 数据库与迁移检测 # 循环检测数据库迁移文件 /loop "运行 prisma migrate status,找出 pending 迁移,分析变更是否安全,应用后验证数据完整性" # Schema 一致性检测 /loop "对比 ORM Model 定义与实际数据库表结构,修复不一致字段,直到 schema diff 为空" # 数据完整性检测 /loop "运行自定义数据校验脚本,找出孤立记录或违反约束的数据,修复或清理,直到校验通过" 九、/loop 项目构建全套检查命令 这是一套针对项目构建全生命周期的 /loop 检测命令合集,覆盖从依赖安装到上线前所有常见检查项。 按语言/框架分类,可直接复制使用。每条命令均为持续检测 + 自动修复的循环模式。 ⚡ 通用项目全套一键检查(推荐入口) # 全套项目健康检查 - 通用版(适配大多数项目) /loop " 按以下顺序对项目执行完整检查,每步失败则自动修复后继续: 1. 检查依赖安装完整性(package.json / requirements.txt 与实际安装是否一致) 2. 运行代码格式化检查并自动修复 3. 运行静态分析 / lint,修复所有错误 4. 运行类型检查,修复类型错误 5. 运行全量单元测试,修复失败用例 6. 运行构建命令,修复构建错误 7. 检查环境变量配置完整性 8. 输出最终健康报告:✅ 全部通过 / ❌ 剩余问题清单 " 🟨 JavaScript / TypeScript 项目 依赖与环境 # 依赖完整性检查 /loop "运行 npm ci,若 node_modules 与 package-lock.json 不一致则删除重装,直到 npm ci 零错误退出" # 依赖版本冲突检测 /loop "运行 npm ls 2>&1 | grep -i 'peer\|invalid\|unmet',逐一解决版本冲突,直到输出干净" # 过时依赖检测 /loop "运行 npm outdated,分析主要依赖的 breaking change,安全升级 patch 和 minor 版本,生成升级报告" # 重复依赖检测 /loop "运行 npm dedupe && npm ls --depth=0,合并重复依赖,直到依赖树最简化" 代码质量 # ESLint 全量修复 /loop "运行 npx eslint . --ext .ts,.tsx,.js,.jsx --fix,分析无法自动修复的错误并手动修复,直到 0 errors 0 warnings" # Prettier 格式化检查 /loop "运行 npx prettier --check .,对不符合规范的文件运行 prettier --write,直到 --check 通过" # TypeScript 严格类型检查 /loop "运行 npx tsc --noEmit --strict,逐一修复类型错误(禁止使用 any 绕过),直到编译 0 错误" # 未使用导出检测 /loop "运行 npx ts-prune,分析并删除确认未使用的导出,直到无残留" # 循环依赖检测 /loop "运行 npx madge --circular --extensions ts,tsx src/,找出循环依赖并重构模块结构,直到无环" 测试 # 单元测试全通过 /loop "运行 npm test -- --watchAll=false,修复失败用例,直到全部 PASS" # 测试覆盖率达标 /loop "运行 npm test -- --coverage --watchAll=false,分析覆盖率报告,补充缺失测试,直到 lines/branches/functions 均 >= 80%" # 快照测试更新 /loop "运行 npm test -- --updateSnapshot --watchAll=false,确认快照变更合理后提交" 构建 # 生产构建检查 /loop "运行 npm run build,分析构建错误和警告,逐一修复,直到构建 0 错误 0 警告" # Next.js 全量构建检查 /loop "运行 npx next build,修复所有页面报错、缺失依赖、无效路由,直到 build 成功并输出 pages 列表" # Bundle 体积分析 /loop "运行 npx next build && npx next-bundle-analyzer,找出超过 200KB 的模块,按需拆分或懒加载,直到首屏 JS < 150KB" # Vite 构建检查 /loop "运行 npx vite build,修复 rollup 打包错误,处理动态导入警告,直到构建产物输出完整" 🐍 Python 项目 依赖与环境 # 虚拟环境依赖检查 /loop "运行 pip check,分析依赖冲突,修复版本约束,直到 No broken requirements" # requirements 同步检查 /loop "对比 pip freeze 与 requirements.txt,补全缺失依赖,移除冗余包,直到两者完全一致" # Poetry 依赖锁定检查 /loop "运行 poetry check && poetry install --sync,修复 pyproject.toml 配置错误,直到锁文件一致" 代码质量 # 全套 Python lint 检查 /loop "依次运行 flake8 . && pylint src/ && mypy .,逐层修复错误,直到三项全部通过" # Black 格式化检查 /loop "运行 black --check .,对失败文件运行 black .,直到 --check 0 files would be reformatted" # isort 导入排序检查 /loop "运行 isort --check-only .,修复导入顺序,直到 isort . --check-only 无输出" # MyPy 严格类型检查 /loop "运行 mypy . --strict,为未标注类型的函数添加类型注解,直到 0 error" # Ruff 快速 lint /loop "运行 ruff check . --fix,处理无法自动修复的规则,直到 All checks passed" 测试 # pytest 全量测试 /loop "运行 pytest -v,分析 FAILED 用例的错误堆栈,修复对应代码,直到 X passed 0 failed" # 覆盖率检查 /loop "运行 pytest --cov=src --cov-report=term-missing --cov-fail-under=80,补充缺失测试直到覆盖率达标" # 异步测试检查 /loop "运行 pytest --asyncio-mode=auto -v,修复所有 async 测试失败,直到全量通过" 构建与打包 # 包构建检查 /loop "运行 python -m build,修复 setup.py / pyproject.toml 配置,直到 dist/ 产物生成成功" # twine 发布前检查 /loop "运行 twine check dist/*,修复 metadata 错误和警告,直到 PASSED" # Docker 镜像构建 /loop "运行 docker build -t myapp:test .,修复 Dockerfile 错误,直到镜像构建成功并 docker run 健康检查通过" ☕ Java / Kotlin 项目(Maven & Gradle) # Maven 全套构建检查 /loop "运行 mvn clean verify,修复编译错误、测试失败、插件报错,直到 BUILD SUCCESS" # Gradle 全套构建检查 /loop "运行 ./gradlew clean build --warning-mode all,修复所有 deprecation 警告和错误,直到 BUILD SUCCESSFUL" # SpotBugs 静态分析 /loop "运行 mvn spotbugs:check,分析 BUG_INSTANCE 报告,修复 HIGH 优先级问题,直到无高危 bug" # Checkstyle 代码规范 /loop "运行 mvn checkstyle:check,修复所有样式违规,直到 0 violations" # JaCoCo 测试覆盖率 /loop "运行 mvn test jacoco:report,分析覆盖率报告,补充测试,直到行覆盖率 >= 80%" # 依赖安全扫描 /loop "运行 mvn dependency-check:check,升级或排除 CVE 高危依赖,直到无 CVSS >= 7.0 的漏洞" 🦀 Go 项目 # Go 全套质量检查 /loop "依次运行 go build ./... && go vet ./... && staticcheck ./...,逐一修复,直到三项 0 输出" # golangci-lint 综合检查 /loop "运行 golangci-lint run ./...,修复所有 linter 报告问题,直到 0 issues" # Go 测试全通过 /loop "运行 go test ./... -v -race,修复竞态条件和失败用例,直到 ok 输出所有包" # Go 覆盖率检查 /loop "运行 go test ./... -coverprofile=coverage.out && go tool cover -func=coverage.out | grep total,补充测试直到总覆盖率 >= 75%" # Go 模块整理 /loop "运行 go mod tidy && go mod verify,修复模块依赖问题,直到两项均 0 错误" # gosec 安全扫描 /loop "运行 gosec ./...,修复 HIGH 和 MEDIUM 安全问题,直到无高危告警" 🐳 Docker / 容器项目 # Dockerfile 最佳实践检查 /loop "运行 hadolint Dockerfile,修复所有 error 和 warning,直到 hadolint 0 issues" # docker-compose 全服务启动检查 /loop "运行 docker-compose up -d && sleep 10 && docker-compose ps,修复 unhealthy 或 exited 的服务,直到所有服务 Up (healthy)" # 镜像体积优化 /loop "运行 docker build -t app:test . && docker images app:test,若镜像 > 500MB 则优化 Dockerfile(多阶段构建、减少层数),直到体积达标" # 镜像安全扫描 /loop "运行 trivy image myapp:latest,修复或排除 CRITICAL 和 HIGH 级别 CVE,直到无 CRITICAL 漏洞" # docker-compose 配置检查 /loop "运行 docker-compose config,修复 YAML 语法错误和配置冲突,直到配置验证通过" ☸️ Kubernetes / 云原生项目 # K8s YAML 配置检查 /loop "运行 kubectl apply --dry-run=client -f k8s/,修复所有 YAML 语法错误和 API 版本问题,直到 dry-run 通过" # Helm Chart 检查 /loop "运行 helm lint ./charts/myapp && helm template ./charts/myapp,修复 Chart 错误,直到 0 error 0 warning" # kube-score 最佳实践检查 /loop "运行 kube-score score k8s/*.yaml,修复 CRITICAL 级别问题(资源限制、健康检查、安全上下文),直到无 CRITICAL" # kubeval Schema 验证 /loop "运行 kubeval k8s/*.yaml --strict,修复 Schema 不符合项,直到 PASS" # 资源配置完整性检查 /loop "检查所有 Deployment 是否配置了 resources.requests/limits、livenessProbe、readinessProbe,补全缺失配置,直到全部完整" 🌐 前端工程项目 # CSS / SCSS 检查 /loop "运行 npx stylelint '**/*.{css,scss}' --fix,修复无法自动修复的样式问题,直到 0 errors" # HTML 可访问性检查 /loop "运行 npx axe-core 对所有页面检测,修复 WCAG AA 级别的可访问性问题,直到无 violations" # 图片资源优化检查 /loop "扫描 public/assets 下图片,对超过 200KB 的 PNG/JPEG 进行压缩优化,直到所有图片 < 200KB" # 死链检测 /loop "运行 npx broken-link-checker http://localhost:3000 -ro,修复所有 404 内部链接,直到 0 broken links" # Web Vitals 检查 /loop "运行 npx lighthouse http://localhost:3000 --output=json,分析 LCP/CLS/FID 指标,优化至 Performance Score >= 90" # PWA 配置检查 /loop "运行 lighthouse --only-categories=pwa http://localhost:3000,修复 PWA 缺失配置(manifest、service worker),直到 PWA 分数 >= 90" 🗄️ 数据库项目 # 迁移文件完整性检查 /loop "运行 prisma migrate status,若有 pending 迁移则 migrate dev,验证数据完整性,直到 Database schema is up to date" # Alembic 迁移检查(Python) /loop "运行 alembic check && alembic upgrade head,修复迁移脚本错误,直到 No new upgrade operations detected" # SQL 语法检查 /loop "使用 sqlfluff lint migrations/ --dialect postgres,修复所有 SQL 风格问题,直到 0 violations" # 数据库索引覆盖检查 /loop "分析所有 ORM 查询,找出缺少索引的 WHERE 和 JOIN 字段,添加索引后运行 EXPLAIN ANALYZE 验证,直到无全表扫描" 📦 Monorepo 项目 # Turborepo 全量构建检查 /loop "运行 turbo run build lint test --force,修复各 workspace 的构建和测试错误,直到所有任务成功" # pnpm workspace 依赖检查 /loop "运行 pnpm -r install && pnpm -r run lint,修复所有工作区的依赖和 lint 错误,直到全部通过" # Nx 影响范围检查 /loop "运行 nx affected --target=test,lint,build --base=main,修复受影响模块的问题,直到 affected 任务全绿" # workspace 版本一致性检查 /loop "检查各 workspace 的公共依赖版本是否一致,统一升级到最新兼容版本,直到无版本不一致" 🔐 安全全套扫描 # 完整安全扫描流水线 /loop " 按顺序执行安全扫描: 1. npm audit --audit-level=high(或 pip-audit / cargo audit)- 修复高危依赖 2. 运行 semgrep --config=auto . - 修复代码层面安全问题 3. 运行 gitleaks detect - 清除泄露的 secrets 4. 检查 CORS、CSP、HTTPS 等 HTTP 安全头配置 5. 检查所有用户输入是否有 SQL 注入 / XSS 防护 输出安全检查报告,直到 0 CRITICAL 0 HIGH " # OWASP 依赖检查 /loop "运行 dependency-check --scan . --failOnCVSS 7,升级所有 CVSS >= 7.0 的依赖,直到检查通过" # Secrets 全量扫描 /loop "运行 trufflehog filesystem . --only-verified,找出所有泄露凭证,替换为环境变量或密钥管理服务,直到扫描无发现" 📋 上线前终极检查 Checklist Loop # 上线前完整检查(全语言通用) /loop " 执行上线前 10 项核心检查,逐项验证并修复: 依赖锁文件是否提交且最新 所有测试通过(单元 + 集成) 代码覆盖率 >= 设定阈值 无 lint 错误 / 类型错误 生产构建成功(无警告) 环境变量 .env.example 完整 数据库迁移文件已就绪 无 console.log / print 调试残留 API 接口文档与实现一致 安全扫描 0 HIGH/CRITICAL 每项输出 ✅ 通过 或 ❌ 问题描述,修复后重新验证该项 " 附录:CLAUDE.md 推荐配置模板 # CLAUDE.md ## 项目概述 ## 技术栈 - 语言:TypeScript / Python / Go - 框架:Next.js / FastAPI / Gin - 数据库:PostgreSQL / Redis ## 常用命令 - 启动开发服务器:`npm run dev` - 运行测试:`npm test` - 构建:`npm run build` - Lint:`npm run lint` ## 代码规范 - 使用 ESLint + Prettier - 提交信息遵循 Conventional Commits - 分支命名:feature/xxx, fix/xxx, chore/xxx ## 禁止操作 - 不得直接修改 main 分支 - 不得提交 .env 文件 - 不得删除迁移文件 文档生成时间:2026年4月 | Claude Code 版本参考:claude-sonnet-4
-
ClaudeCode指定 plan文件的存储位置 方案一:项目级配置(推荐) 在你的项目目录下的 .claude/settings.json 里添加: { "plansDirectory": "./docs/plans" } 这样 plan 文件就会创建在项目根目录的 docs/plans/ 文件夹下,还可以提交到 git。 方案二:全局配置 修改用户级别的配置文件 ~/.claude/settings.json(Windows 上是 C:\Users\用户名.claude\settings.json): { "plansDirectory": "D:/my-projects/claude-plans" } 路径写法说明 写法效果 "./plans"相对于工作区根目录" ./docs/plans"项目内的 docs 子目录 "D:/my-projects/plans"Windows 绝对路径 推荐把 plansDirectory 加到项目的 .claude/settings.json(而不是用户级别),这样团队成员克隆仓库后,大家的 plan 都会存到同一个位置。 codewithmukesh
-
-
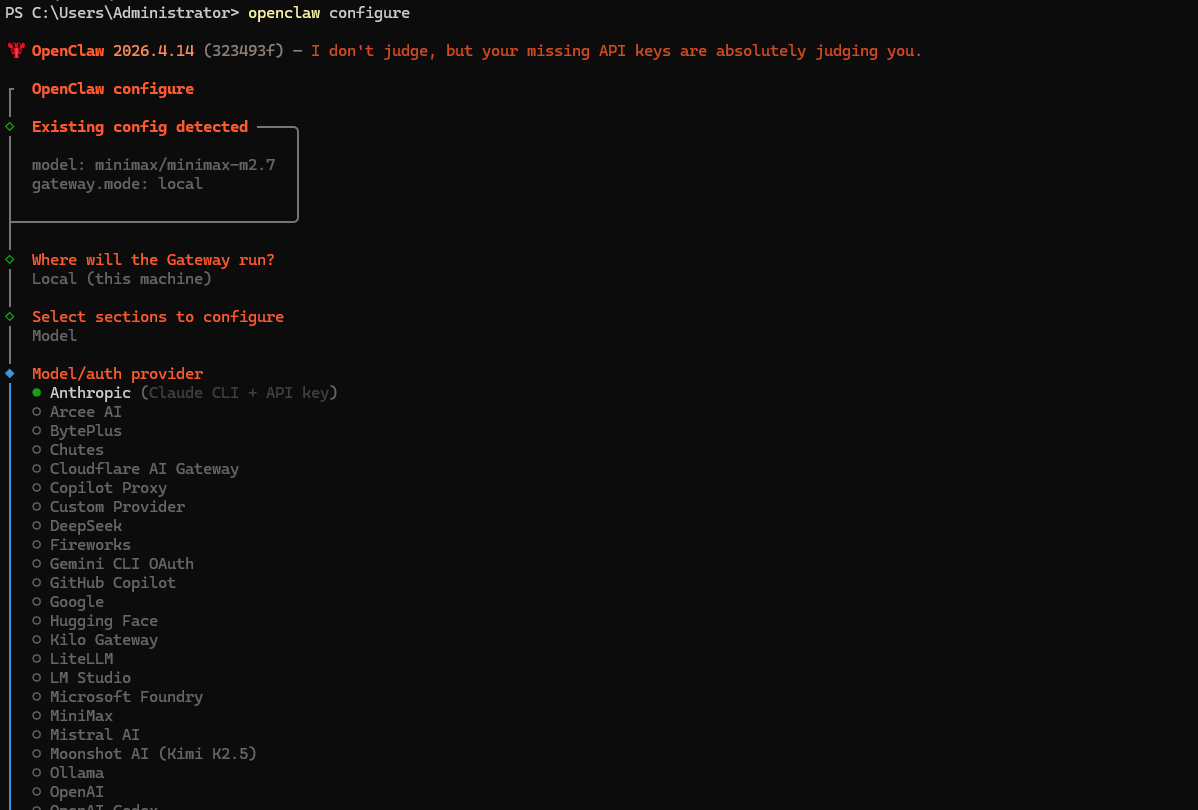 OpenClaw安装问题修复和常用命令 一、查看面板信息 openclaw dashboard PS C:\Users\Administrator> openclaw dashboard OpenClaw 2026.4.14 (323493f) — I'm the middleware between your ambition and your attention span. Dashboard URL: http://127.0.0.1:18789/#token=93f31ddddc31ae2d6802b238987f1148c2a5b3cd06f68e92 Copied to clipboard. Opened in your browser. Keep that tab to control OpenClaw. PS C:\Users\Administrator> 二、重新调用配置 运行 openclaw configure 二、windows运行简单方案 打开目录 C:\Users\Administrator.openclaw 用powershell 运行 gateway.cmd 可以看到 openclaw.json 配置错误信息和运行结果状态。
OpenClaw安装问题修复和常用命令 一、查看面板信息 openclaw dashboard PS C:\Users\Administrator> openclaw dashboard OpenClaw 2026.4.14 (323493f) — I'm the middleware between your ambition and your attention span. Dashboard URL: http://127.0.0.1:18789/#token=93f31ddddc31ae2d6802b238987f1148c2a5b3cd06f68e92 Copied to clipboard. Opened in your browser. Keep that tab to control OpenClaw. PS C:\Users\Administrator> 二、重新调用配置 运行 openclaw configure 二、windows运行简单方案 打开目录 C:\Users\Administrator.openclaw 用powershell 运行 gateway.cmd 可以看到 openclaw.json 配置错误信息和运行结果状态。 -
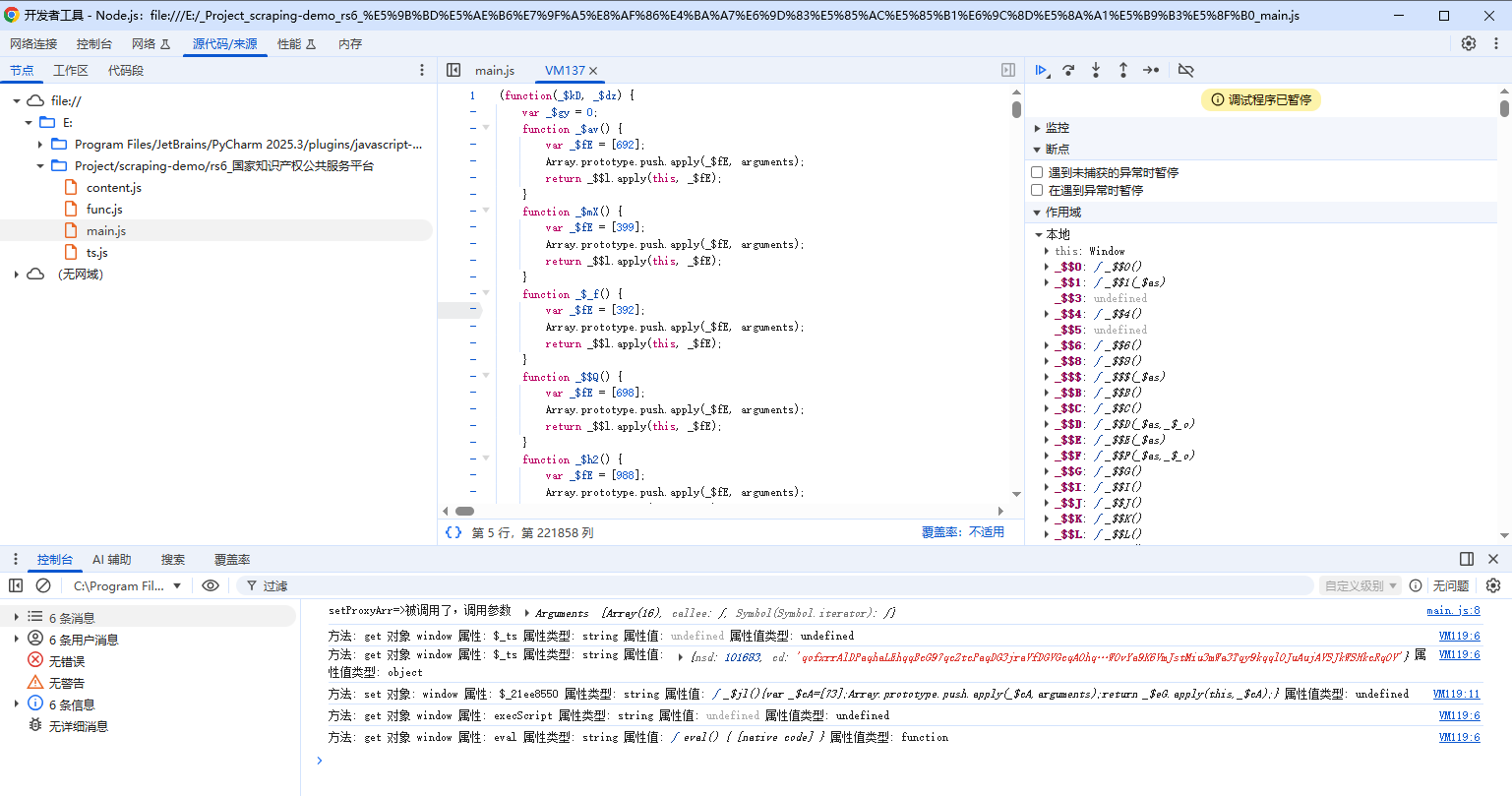 用 Chrome DevTools 调试 Node.js 从 v 6.3.0 开始,可以用 Chrome Developer Tools 调试 Node.js。以下是操作步骤: 在自己的机器上安装 Node.js v6.3.0 或更高版本。 使用 --inspect-brk 标志运行 node(例如:node --inspect-brk index.js)。 在 Chrome 中打开一个新标签页,并在地址栏中输入 about:inspect 并回车。你应该会看到类似下面的截图: 单击 Open dedicated DevTools for Node,会打开一个新窗口,在窗口中连接到你的 Node.js 实例。
用 Chrome DevTools 调试 Node.js 从 v 6.3.0 开始,可以用 Chrome Developer Tools 调试 Node.js。以下是操作步骤: 在自己的机器上安装 Node.js v6.3.0 或更高版本。 使用 --inspect-brk 标志运行 node(例如:node --inspect-brk index.js)。 在 Chrome 中打开一个新标签页,并在地址栏中输入 about:inspect 并回车。你应该会看到类似下面的截图: 单击 Open dedicated DevTools for Node,会打开一个新窗口,在窗口中连接到你的 Node.js 实例。